golang的pprof与火焰图实战
题记
性能分析是一种动态程序分析方法,用于收集程序运行时的信息以研究程序性能行为。在日常开发中对定位和优化性能问题非常重要,能够帮助我们以最小的投入获得最大的性能优化回报。
1、pprof是什么
在Go语言中,pprof是用于可视化和分析性能分析数据的工具,pprof以profile.proto读取分析样本的集合,并生成报告以可视化并帮助分析数据(支持文本和图形报告)。
2、pprof作用
Go的pprof提供了2个工具供我们使用,runtime/pprof中是它的源码,net/http/pprof对源码做了简单封装,能让你在http服务中直接使用。它可以采样程序运行时的CPU、堆内存、Goroutine、锁竞争、阻塞调用、系统线程的使用情况。然后通过可视化终端或网页的形式展示给用户,用户可以通过列表、调用图、源码、火焰图、反汇编等视图去展示采集到的性能指标。

pprof指标采样的维度:
- CPU(profile)
- CPU Profiling:CPU 分析,按照一定的频率采集所监听的应用程序 CPU(含寄存器)的使用情况,可确定应用程序在主动消耗 CPU 周期时花费时间的位置。
- 报告CPU的使用情况,定位到热点(消耗CPU周期最多的)代码。默认情况下Go以100HZ的频率进行CPU采样
- Goroutine
- Goroutine Profiling: Goroutine 分析,可以对当前应用程序正在运行的 Goroutine 进行堆栈跟踪和分析。这项功能在实际排查中会经常用到,因为很多问题出现时的表象就是 Goroutine 暴增,而这时候我们要做的事情之一就是查看应用程序中的 Goroutine 正在做什么事情,因为什么阻塞了,然后再进行下一步。
- 系统线程
- 获取导致创建 OS 线程的 goroutine 堆栈
- 堆内存/内存剖析(heap)
- Memory Profiling:内存分析,在应用程序进行堆分配时记录堆栈跟踪,用于监视当前和历史内存使用情况,以及检查内存泄漏。
- 包含每个 goroutine 分配大小,分配堆栈等。
- 每分配 runtime.MemProfileRate(默认为512K) 个字节进行一次数据采样。
- 内存剖析(allocs):报告所有内存分配历史
- 阻塞操作
- Block Profiling:阻塞分析,记录 Goroutine 阻塞等待同步(包括定时器通道)的位置,默认不开启,需要调用
runtime.SetBlockProfileRate进行设置。 - 获取导致阻塞的 goroutine 堆栈(如 channel, mutex 等),使用前需要先调用
runtime.SetBlockProfileRate
- Block Profiling:阻塞分析,记录 Goroutine 阻塞等待同步(包括定时器通道)的位置,默认不开启,需要调用
- 锁竞争
- Mutex Profiling:互斥锁分析,报告互斥锁的竞争情况,默认不开启,需要调用
runtime.SetMutexProfileFraction进行设置。
- Mutex Profiling:互斥锁分析,报告互斥锁的竞争情况,默认不开启,需要调用
- 执行追踪(trace):追踪当前应用程序的执行栈
3、pprof使用模式
- Report generation:报告生成
- Interactive terminal use:交互式终端
- Web interface:Web 界面
4、采样方式
| 方式名称 | 如何使用 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|---|
| runtime/pprof | 手动调用【runtime.StartCPUProfile、runtime.StopCPUProfile】等API来进行数据的采集。采集程序(非 Server)的指定区块的运行数据进行分析。 | 灵活性高、按需采集。 | 工具型应用(比如说定制化的分析小工具、集成到公司监控系统)。这种应用运行一段时间就结束。 | |
| net/http/pprof | 通过http服务来获取Profile采样文件。 import _ "net/http/pprof"。基于 HTTP Server 运行,并且可以采集运行时数据进行分析。net/http/pprof中只是使用runtime/pprof包来进行封装了一下,并在http端口上暴露出来 |
简单易用 | 在线服务(一直运行着的程序) | |
| go test | 通过命令go test -bench . -cpuprofile cpu.prof来进行采集数据。 |
针对性强、细化到函数 | 进行某函数的性能测试 |
上面的 pprof 开启后,每隔一段时间就会采集当前程序的堆栈信息,获取函数的 cpu、内存等使用情况。通过对采样的数据进行分析,形成一个数据分析报告。
pprof 以 profile.proto 的格式保存数据,然后根据这个数据可以生成可视化的分析报告,支持文本形式和图形形式报告。profile.proto 里具体的数据格式是 protocol buffers。
那用什么方法来对数据进行分析,从而形成文本或图形报告?用一个命令行工具 go tool pprof 。
4.1、go test
- cpu 使用分析:-cpuprofile=cpu.pprof
- 内存使用分析:-benchmem -memprofile=mem.pprof
- block分析:-blockprofile=block.pprof
运行命令采样数据:
1 | go test -bench=. -run=none -benchmem -memprofile=mem.pprof |
4.2、runtime/pprof
除了注入 http handler 和 go test 以外,我们还可以在程序中通过 pprof 所提供的 Lookup 方法来进行相关内容的采集和调用,其一共支持六种类型,分别是:goroutine、threadcreate、heap、block、mutex,代码如下:
1 | type LookupType int8 |
接下来我们只需要对该方法进行调用就好了,其提供了 io.Writer 接口,也就是只要实现了对应的 Write 方法,我们可以将其写到任何支持地方去,如下:
1 | ... |
在上述代码中,我们将采集结果写入到了控制台上,我们可以进行一下验证,调用 http://127.0.0.1:6060/lookup/heap,控制台输出结果如下:
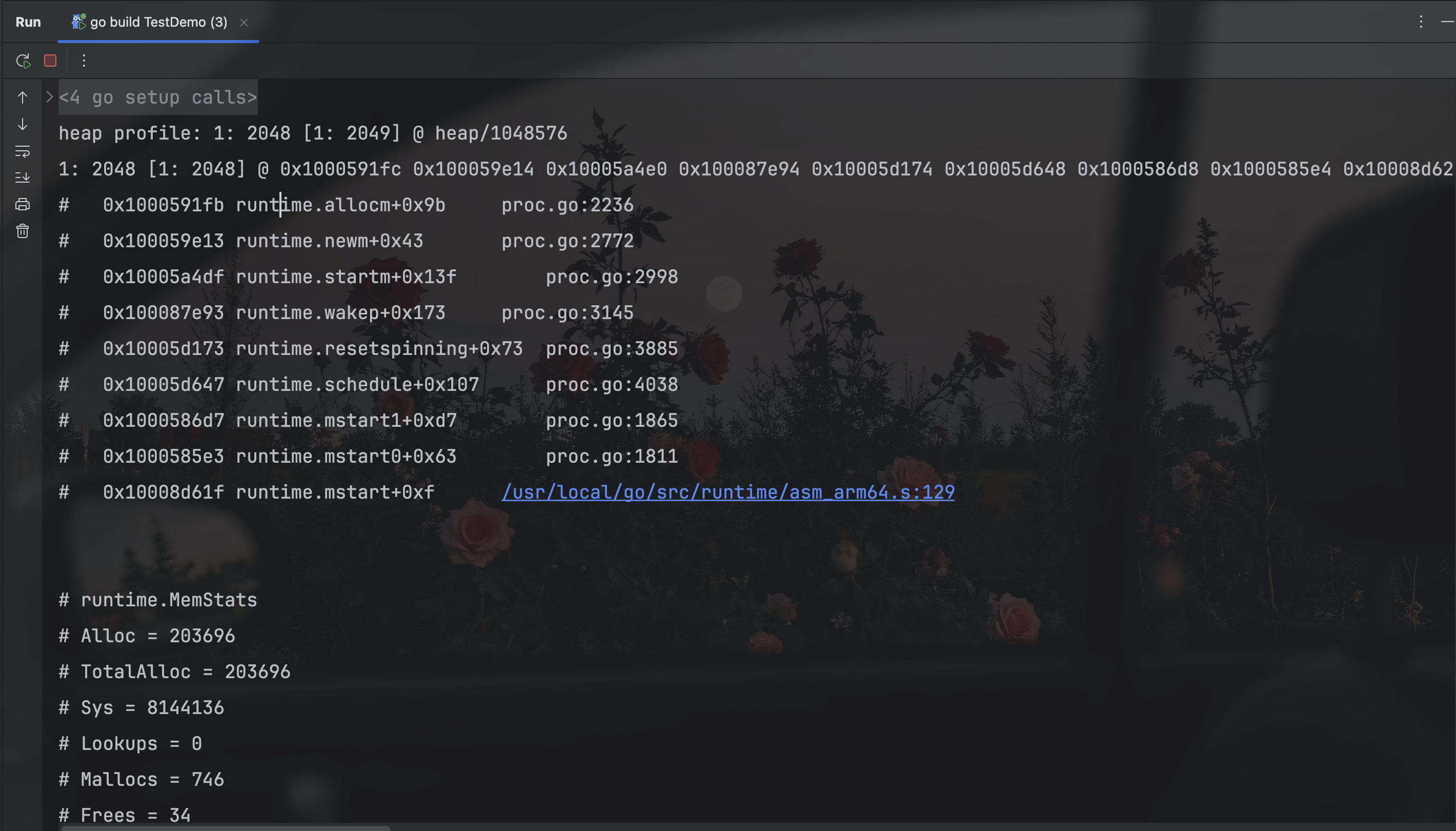
本章节所有测试都是使用的main.go文件,子章节只会展示我的测试代码,统一用一个入口main函数。main函数如下:
1 | package main |
1 | go run main.go |
结果分析方式也是一样的,如下:
1 | go tool pprof cpu.prof |
或者通过暴露http端口的方式,可以查看更多类型的图。
1 | go tool pprof -http=:6060 cpu.prof |
4.2.1、采集CPU(CPU 占用过高)
1 | func CollectCpu() { |
4.2.2、采集内存(heap-内存占用过高)
作用:看哪些方法分配了最多的内存
1 | const ( |
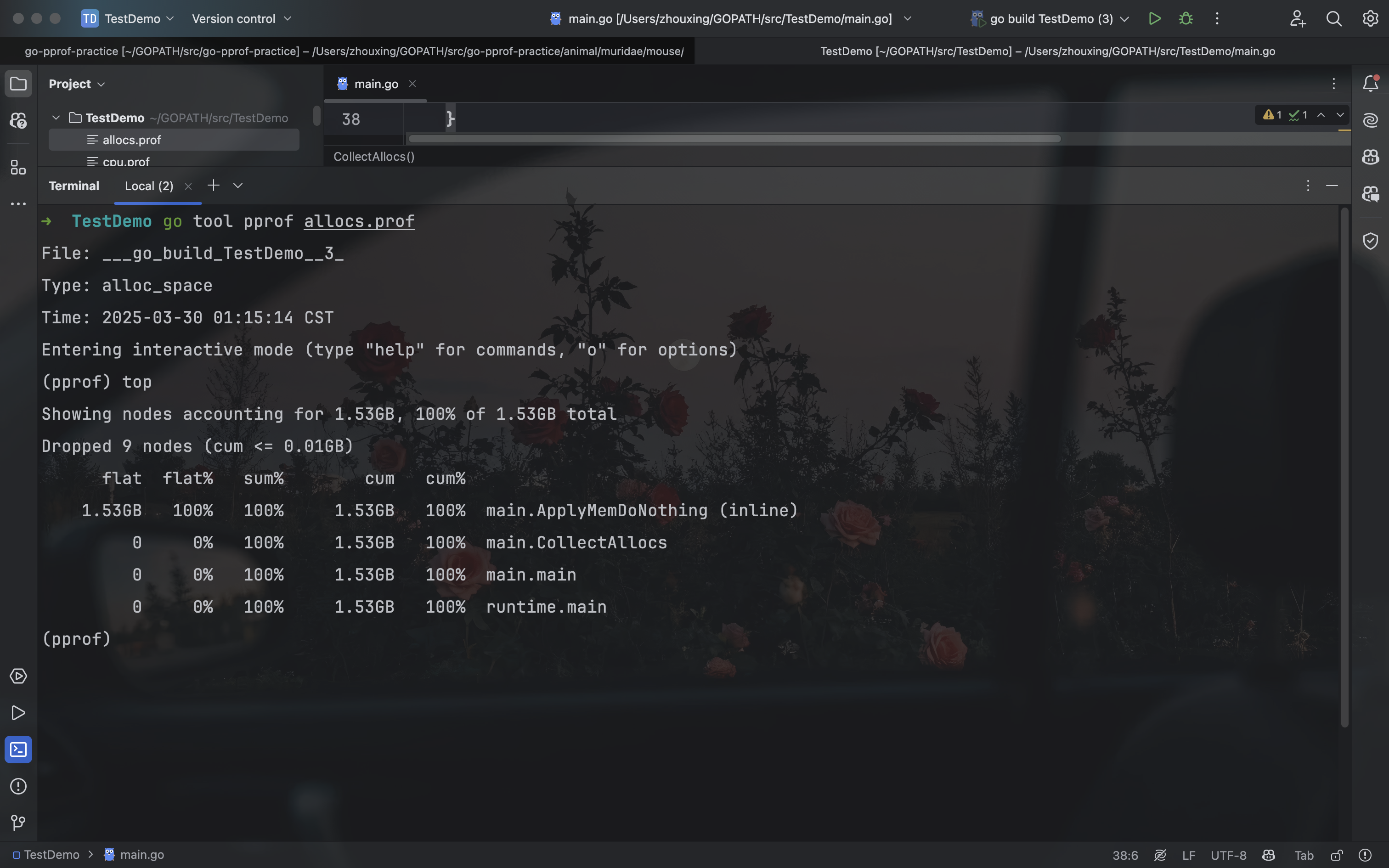
4.2.3、采集内存(allocs-频繁内存回收)
获取程序运行依赖,所有内存分配的历史
1 | func ApplyMemDoNothing() { |
为了获取程序运行过程中 GC 日志,我们需要先退出炸弹程序,再在重新启动前赋予一个环境变量,同时为了避免其他日志的干扰,使用 grep 筛选出 GC 日志查看:由于内存的申请与释放频度是需要一段时间来统计的,所有我们保证炸弹程序已经运行了几分钟之后,再结束:
1 | go build main.go |
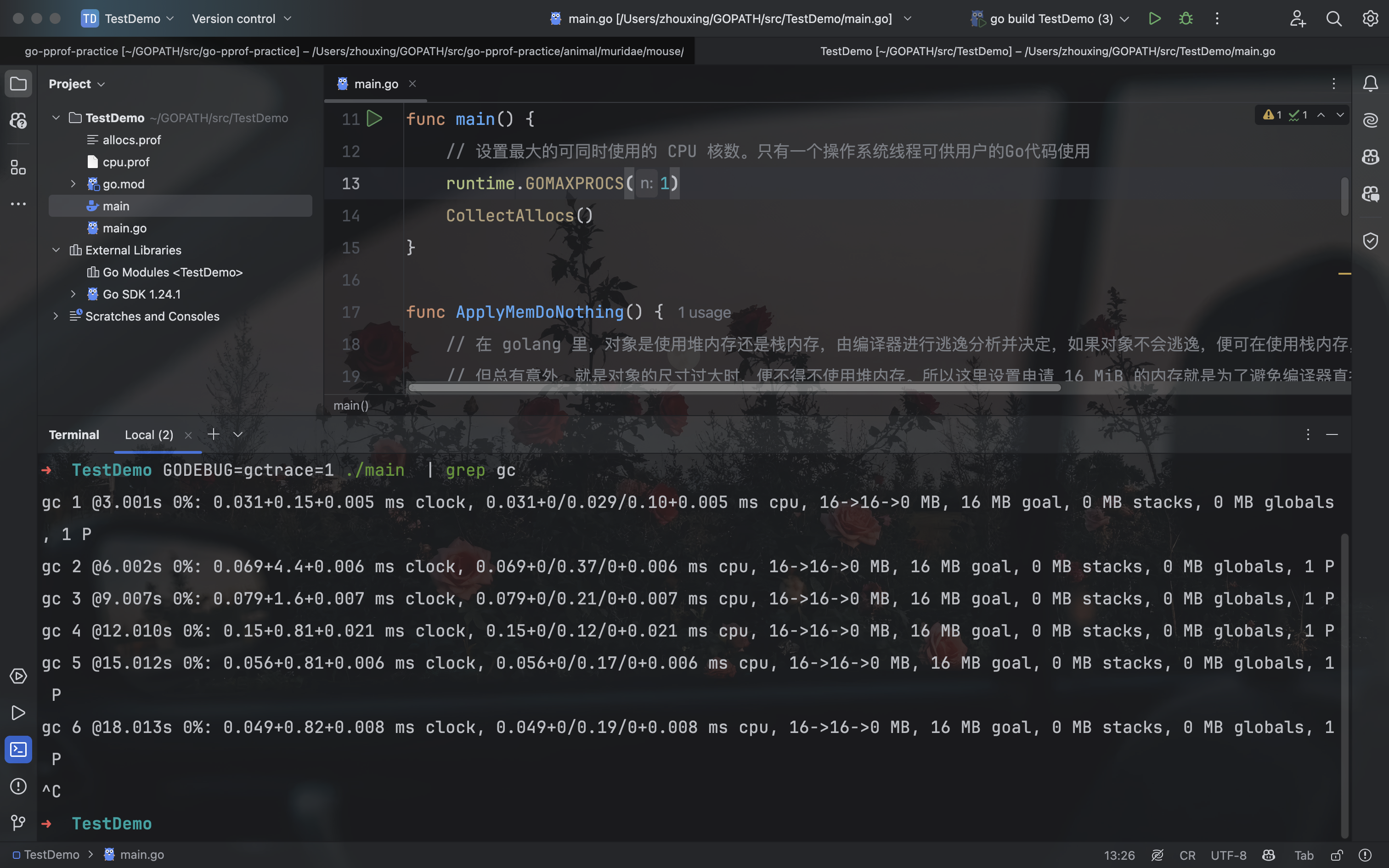
可以看到,GC 差不多每 3 秒就发生一次,且每次 GC 都会从 16MB 清理到几乎 0MB,说明程序在不断的申请内存再释放,这是高性能 golang 程序所不允许的。如果你希望进一步了解 golang 的 GC 日志可以查看《如何监控 golang 程序的垃圾回收》,为保证实验节奏,这里不做展开。所以接下来使用 pprof 排查时,我们在乎的不是什么地方在占用大量内存,而是什么地方在不停地申请内存,这两者是有区别的。
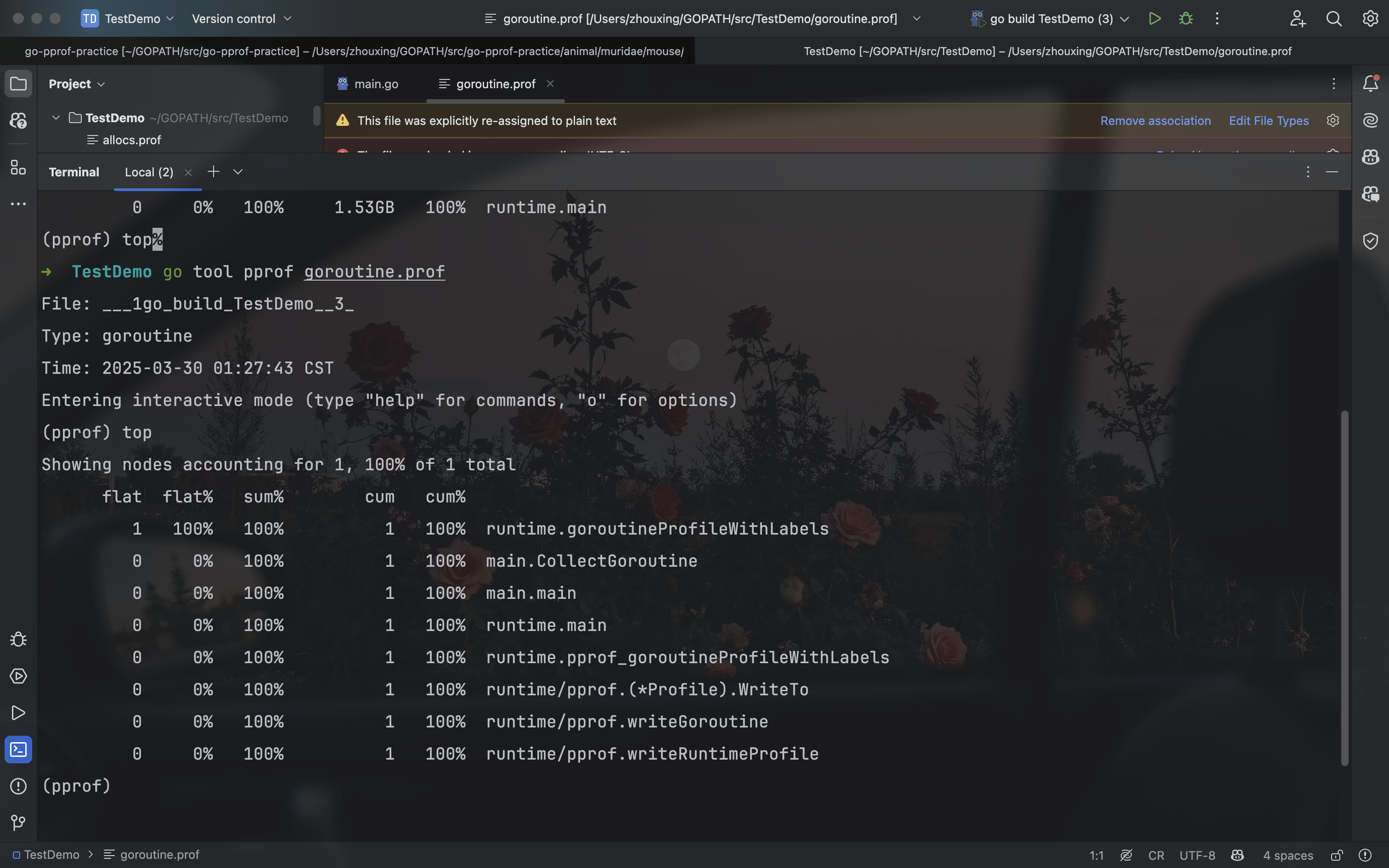
4.2.4、采集goroutine(协程泄露)
1 | func CollectGoroutine() { |
4.2.5、采集mutex(锁的争用)
1 | func CollectMutex() { |
4.2.6、采集block(阻塞操作)
1 | func CollectBlock() { |
4.3、net/http/pprof
1 | package main |
通过代码中的关键两步,执行起来就可以通过看到对应的数据:http://127.0.0.1:6060/debug/pprof/
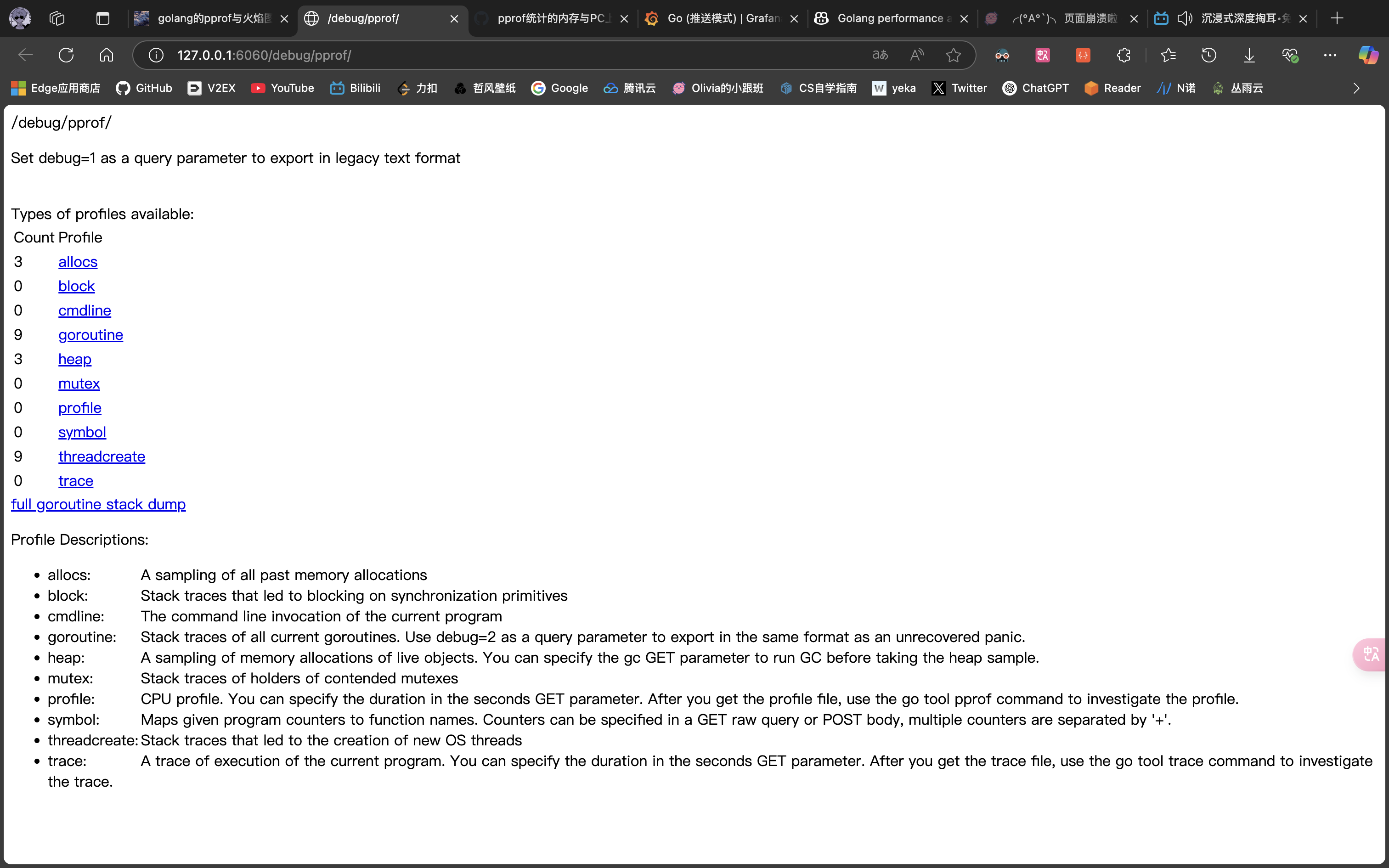
5、采样的数据内容
| 类型 | 描述 | url |
|---|---|---|
| allocs | 内存分配情况的采样信息,过去所有内存抽样情况 | $host/debug/pprof/allocs?debug=1 |
| blocks | 阻塞操作情况的采样信息,同步阻塞时程序栈跟踪的一些情况 | $host/debug/pprof/block?debug=1 |
| cmdline | 显示程序启动命令参数及其参数 | |
| goroutine | 显示当前所有协程的堆栈信息 | |
| heap | 堆上的内存分配情况的采样信息,活动对象的内存分配情况 | $host/debug/pprof/heap?debug=1 |
| mutex | 锁竞争情况的采样信息,互斥锁持有者的栈帧情况 | $host/debug/pprof/mutex?debug=1 |
| profile | cpu占用情况的采样信息,点击会下载文件,cpu profile,点击时会得到一个文件,然后可以用 go tool pprof 命令进行分析 | $host/debug/pprof/profile |
| threadcreate | 系统线程创建情况的采样信息,创建新 OS 线程的堆栈跟踪情况 | $host/debug/pprof/threadcreate?debug=1 |
| trace | 程序运行跟踪信息,当前程序执行的追踪情况,点击时会得到一个文件,可以用 go tool trace 命令来分析这个文件 | $host/debug/pprof/trace |
6、数据分析方式
6.1、命令行
核心命令:go tool pprof <binary> <source>
binary:是应用的二进制文件,用来解析各种符号;
source:代表生成的分析数据来源,可以是本地文件(前文生成的cpu.prof),也可以是http地址(比如:go tool pprof http://127.0.0.1:9090/debug/pprof/profile)
需要注意的是:较大负载的情况下(要不就故意写故障代码,或者就模拟访问压力)获取的有效数据更有意义,如果处于空闲状态,得到的结果可能意义不大
通过工具go tool pprof打开URL或文件后,会显示一个 (pprof)提示符,你可以使用以下命令:
| 命令 | 参数 | 说明 |
|---|---|---|
| gv | [focus] | 将当前概要文件以图形化和层次化的形式显示出来。当没有任何参数时,在概要文件中的所有采样都会被显示如果指定了focus参数,则只显示调用栈中有名称与此参数相匹配的函数或方法的采样。 focus参数应该是一个正则表达式需要dot、gv命令,执行下面的命令安装:sudo apt-get install graphviz |
| web | [focus] | 生成 svg 热点图片,与gv命令类似,web命令也会用图形化的方式来显示概要文件。但不同的是,web命令是在一个Web浏览器中显示它 |
| list | [routine_regexp] | 列出名称与参数 routine_regexp代表的正则表达式相匹配的函数或方法的相关源代码 |
| weblist | [routine_regexp] | 在Web浏览器中显示与list命令的输出相同的内容。它与list命令相比的优势是,在我们点击某行源码时还可以显示相应的汇编代码 |
| top[N] | [–cum] | top命令可以以本地采样计数为顺序列出函数或方法及相关信息如果存在标记 –cum则以累积采样计数为顺序默认情况下top命令会列出前10项内容。但是如果在top命令后面紧跟一个数字,那么其列出的项数就会与这个数字相同。默认显示 flat 前10的函数调用,可使用 -cum 以 cum 排序 |
| traces | 打印所有采集的样本 | |
| disasm | [routine_regexp] | 显示名称与参数 routine_regexp相匹配的函数或方法的反汇编代码。并且,在显示的内容中还会标注有相应的采样计数 |
| callgrind | [filename] | 利用callgrind工具生成统计文件。在这个文件中,说明了程序中函数的调用情况。如果未指定 filename参数,则直接调用kcachegrind工具。kcachegrind可以以可视化的方式查看callgrind工具生成的统计文件 |
| help | 显示帮助 | |
| quit | 退出 |
开始分析前文生成的cpu.prof:
1 | go tool pprof cpu.prof |
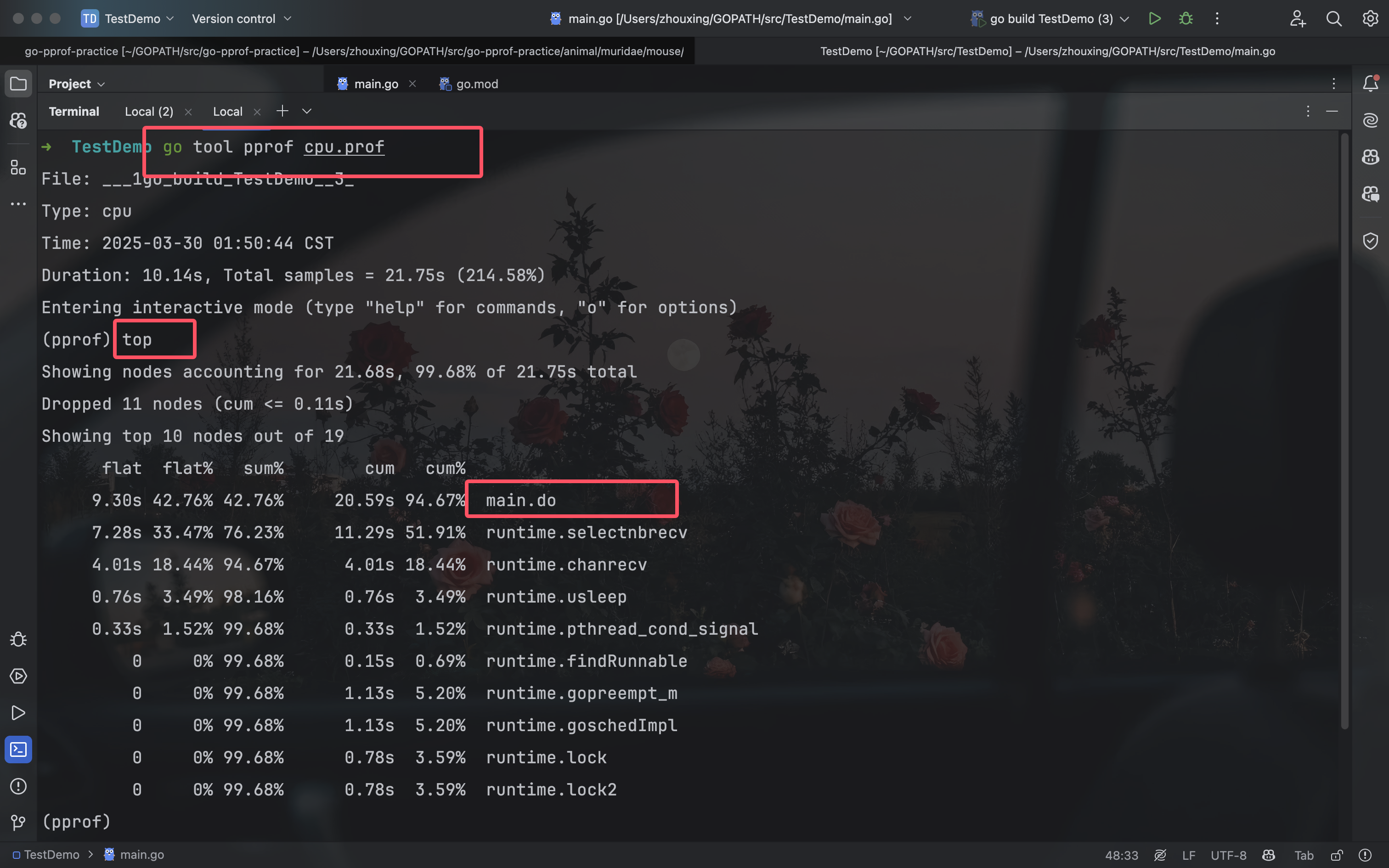
| 类型 | 描述 | 举例 |
|---|---|---|
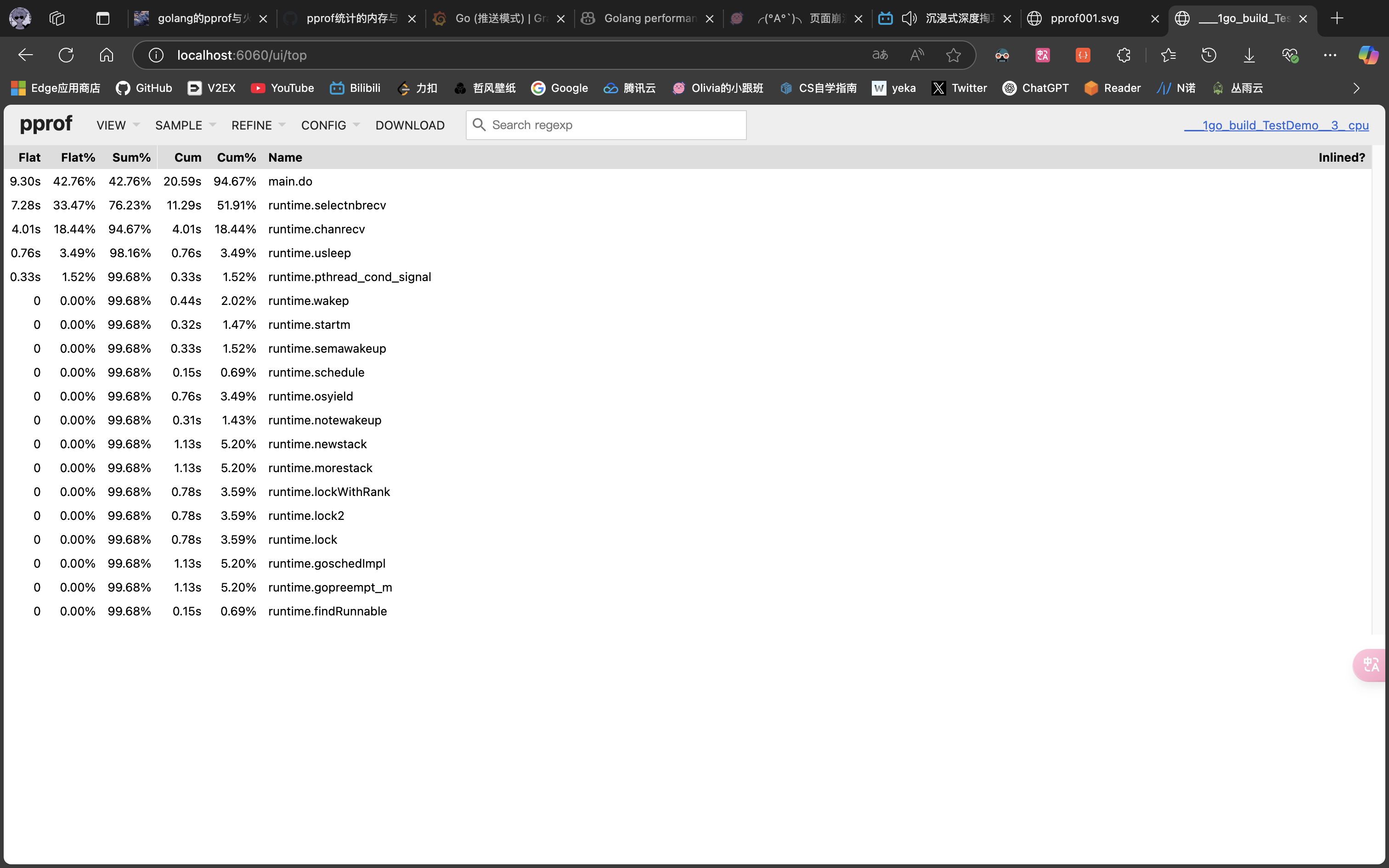
| flat | 该函数占用CPU的耗时,不包含当前函数调用其它函数并等待返回的时间 | selectnbrecv占用CPU的耗时是7.28s |
| flat% | 该函数占用CPU的耗时的百分比 | selectnbrecv耗时:7.28s,cpu总耗时:21.75s,7.28/21.75=33.47% |
| sum% | 前面所有flat总和,top命令中排在它上面的函数以及本函数flat%之和 | chanrecv:42.76%+33.47%+18.44%=94.67% |
| cum | 当前函数加上该函数调用其它函数的累计CPU耗时,该指标包含子函数耗时 | chanrecv:4.01s本身没调用其他函数 |
| cum% | 当前函数加上该函数调用其它函数的累计CPU耗时的百分比 | 4.01/21.75=18.44% |
| 最后一列 | 当前函数名称 | - |
什么时候Flat==cum?Flat是当前函数耗时,Cum是当前函数和调用函数累计耗时,他俩相等,代表当前函数没有调用别的函数。什么时候Flat==0?函数中只有其它函数的调用。
上面的命令解析,发现do函数有点问题。此时通过命令:list funcName,来进行查看具体的位置
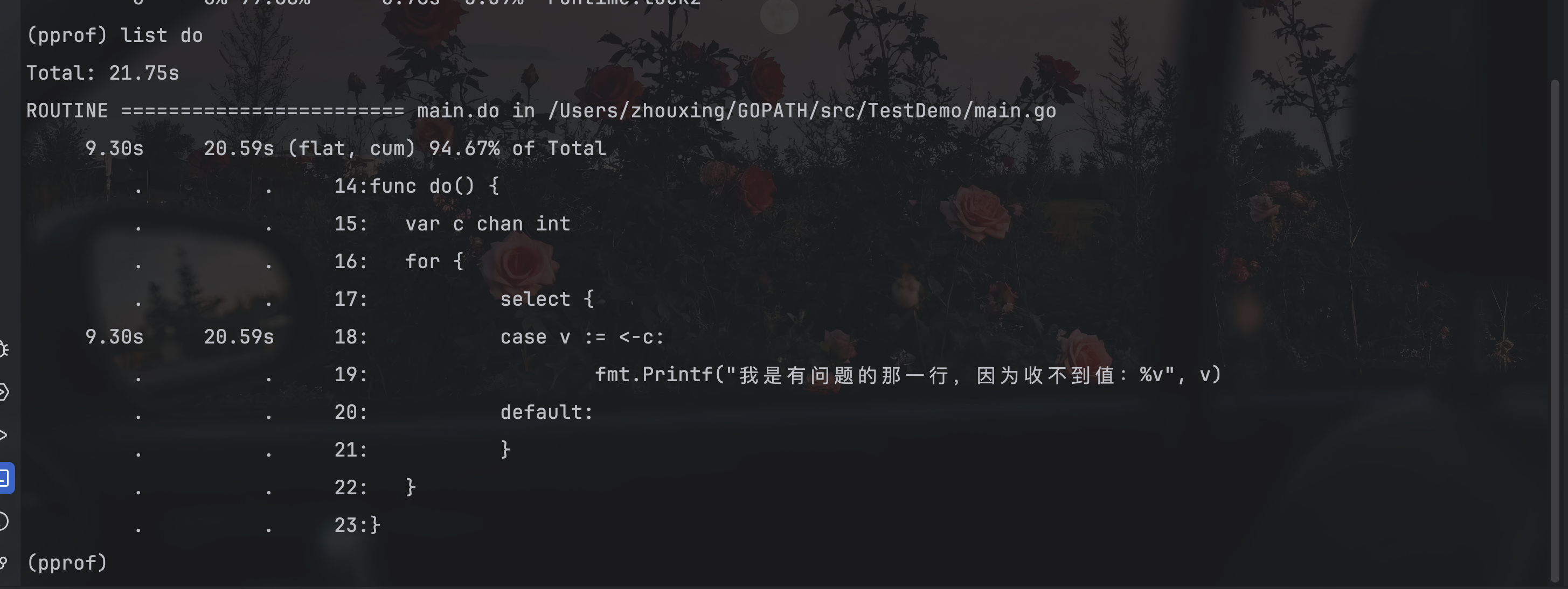
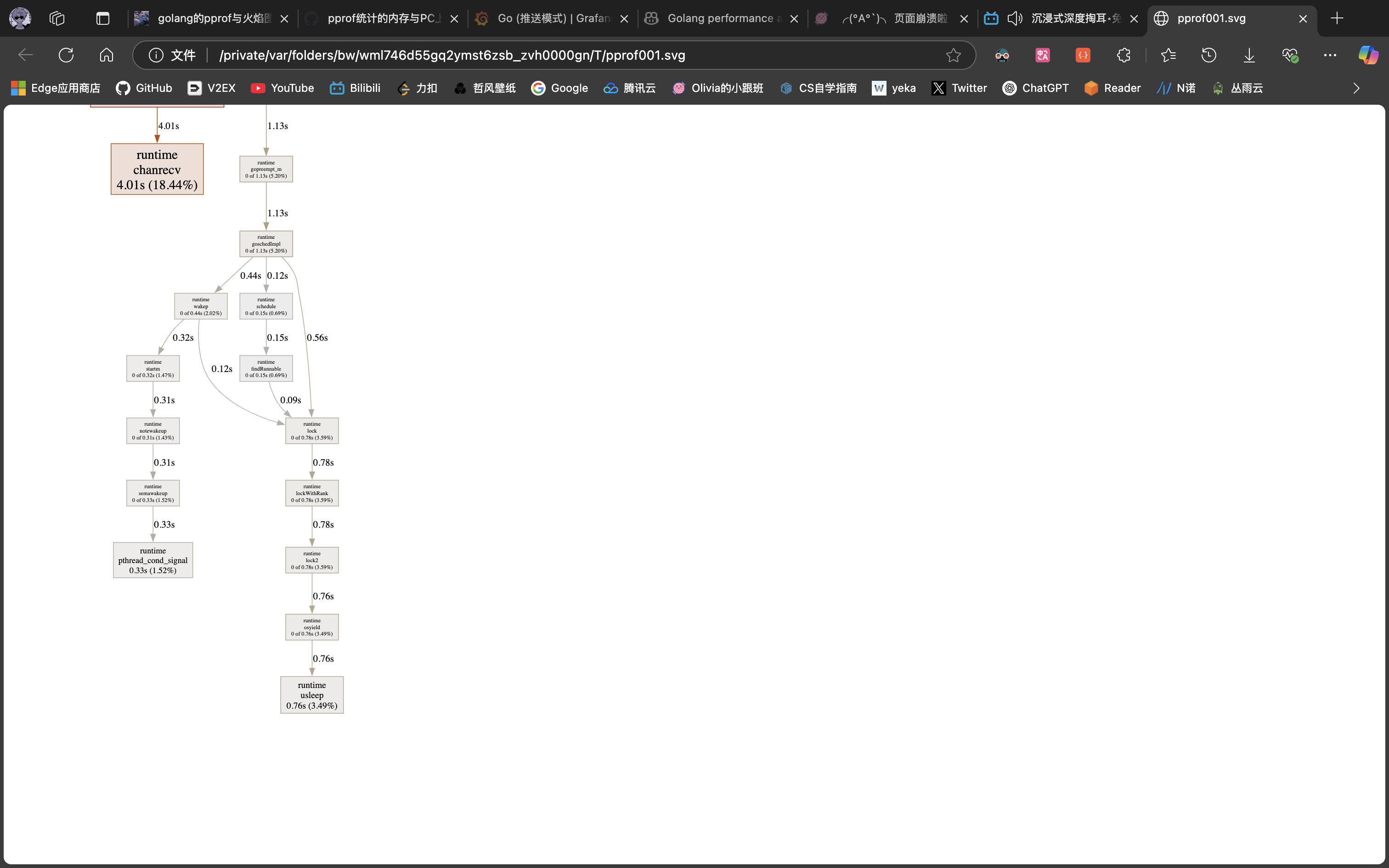
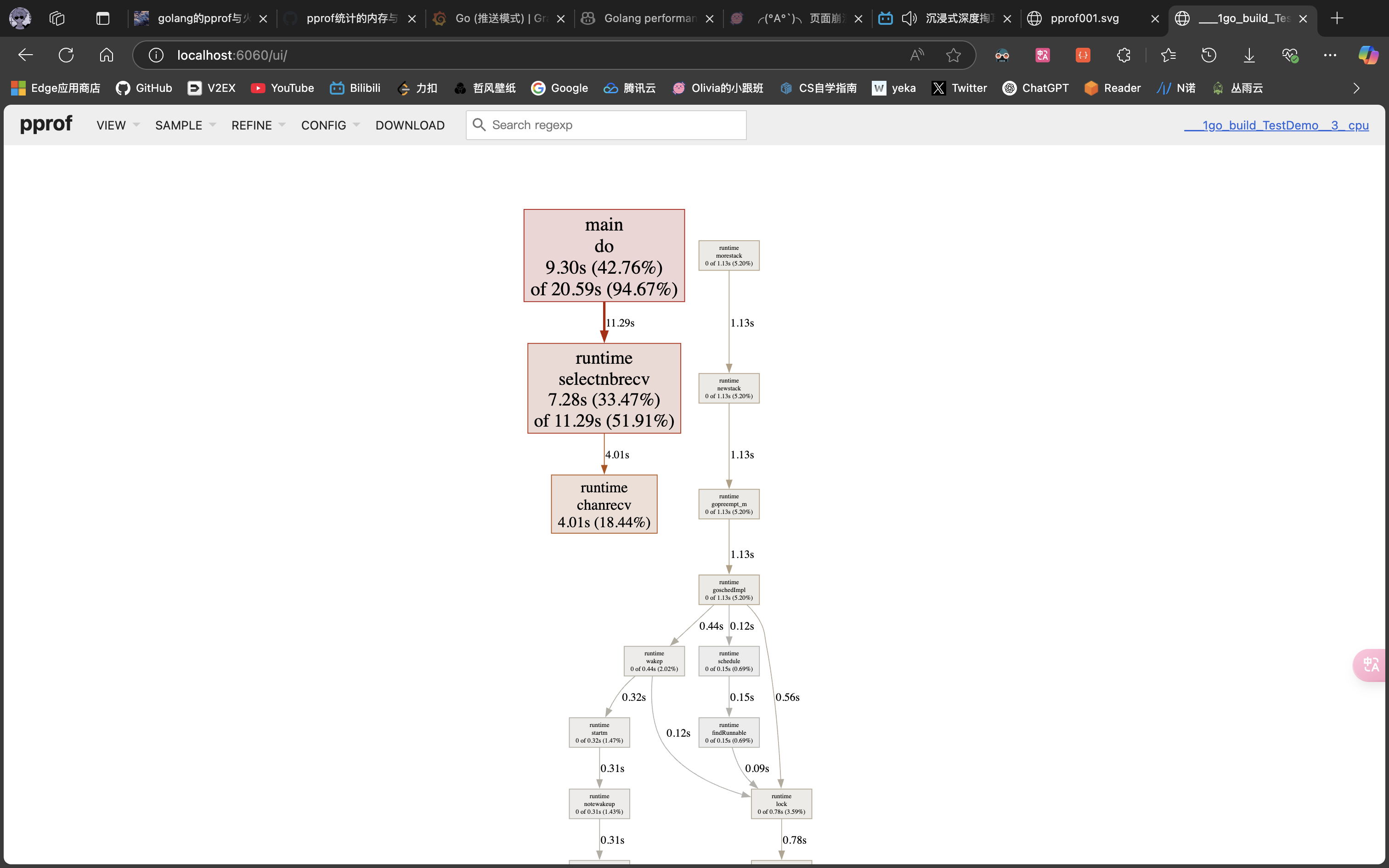
1.在前文的对话框中继续输入:web。即可生成pprof001.svg的页面。
2.执行命令:
go tool pprof -pdf cpu.prof,会生成profile001.pdf的pdf文件。(参数可选text、pdf、svg),不管哪种形式,都会得到以下图片:
6.2、可视化界面方式
执行命令:go tool pprof -http=:6060 cpu.prof
- Top(同前文gdb交互页面的top命令)
- Graph(同前文gdb交互页面的web命令)
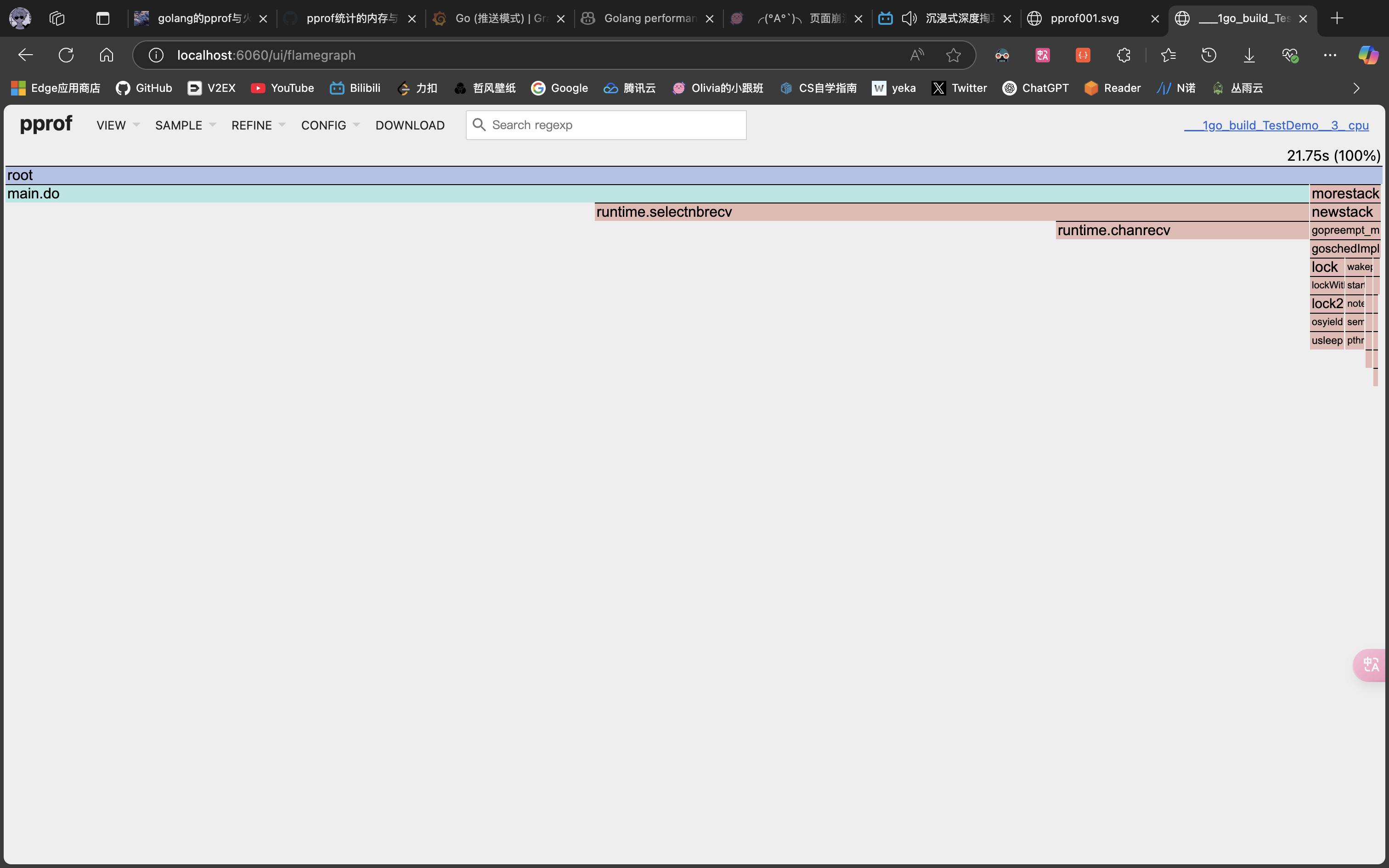
Flame Graph(火焰图)
这里的颜色是随机分布的,只是看起来像火焰。调用顺序由上到下,每一块代表一个函数,越大代表占用 CPU 的时间更长。同时它也可以支持点击块深入进行分析。
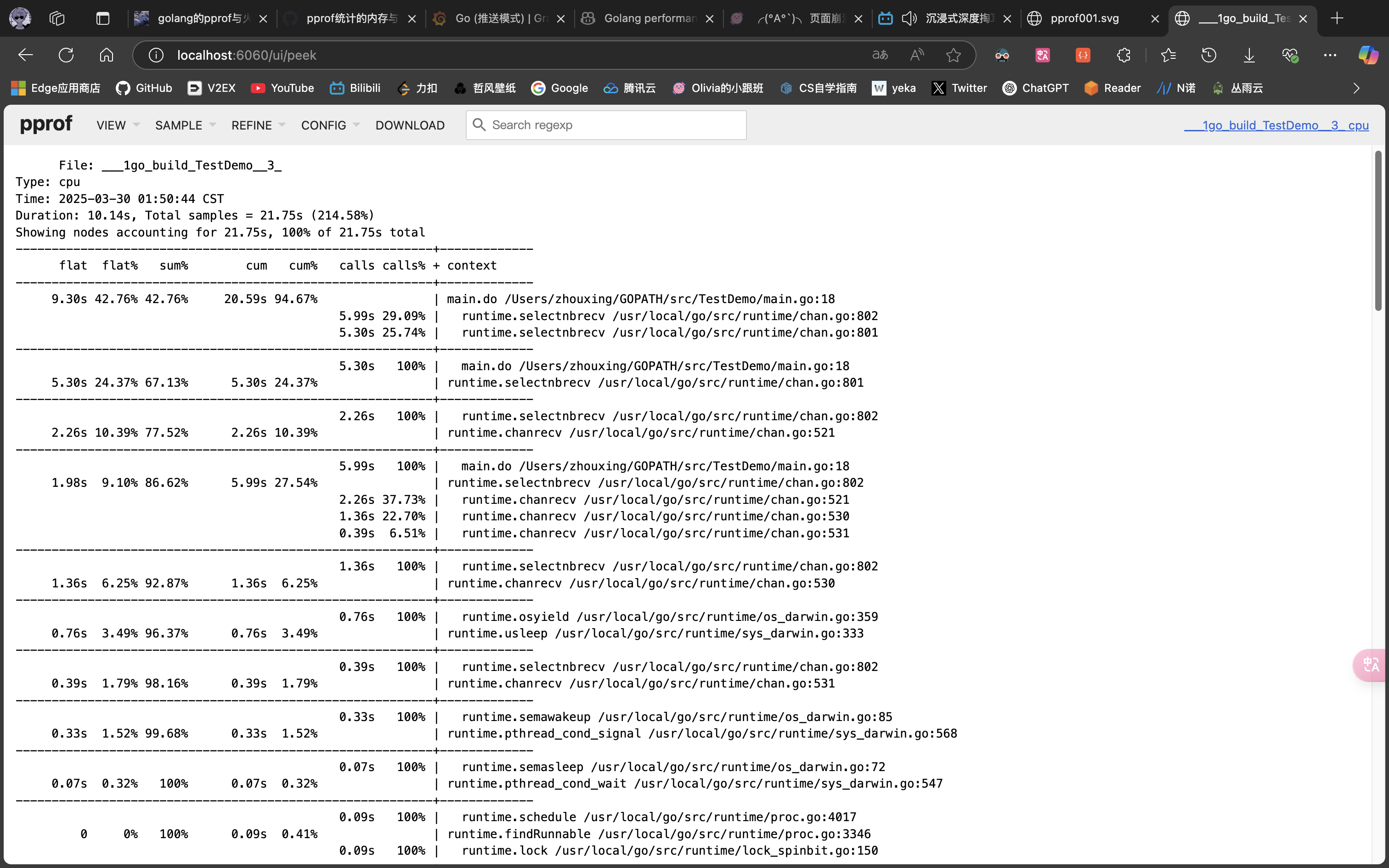
- Peek(详细=树结构)
- Source(同前文gdb交互页面的list FuncName命令)
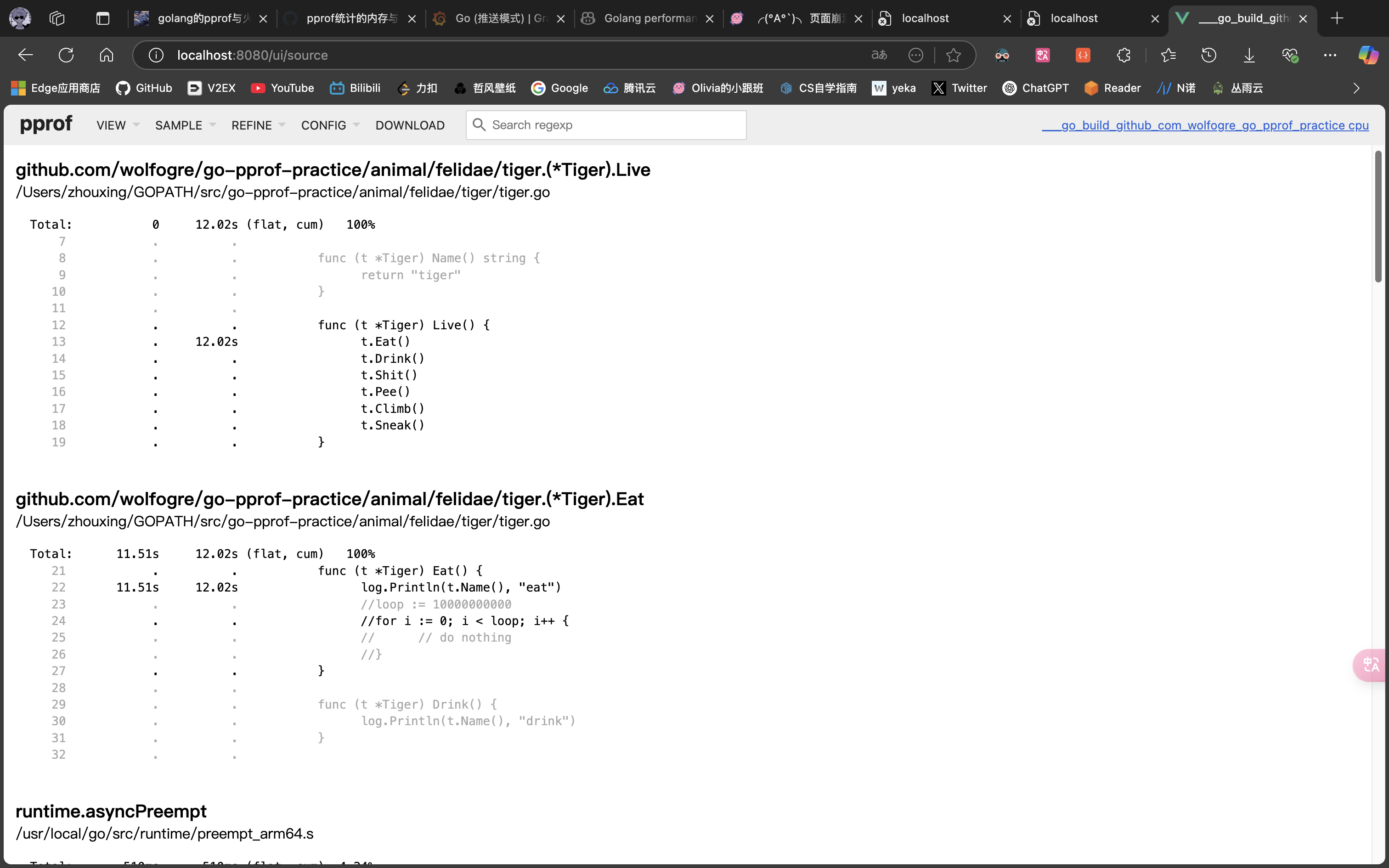
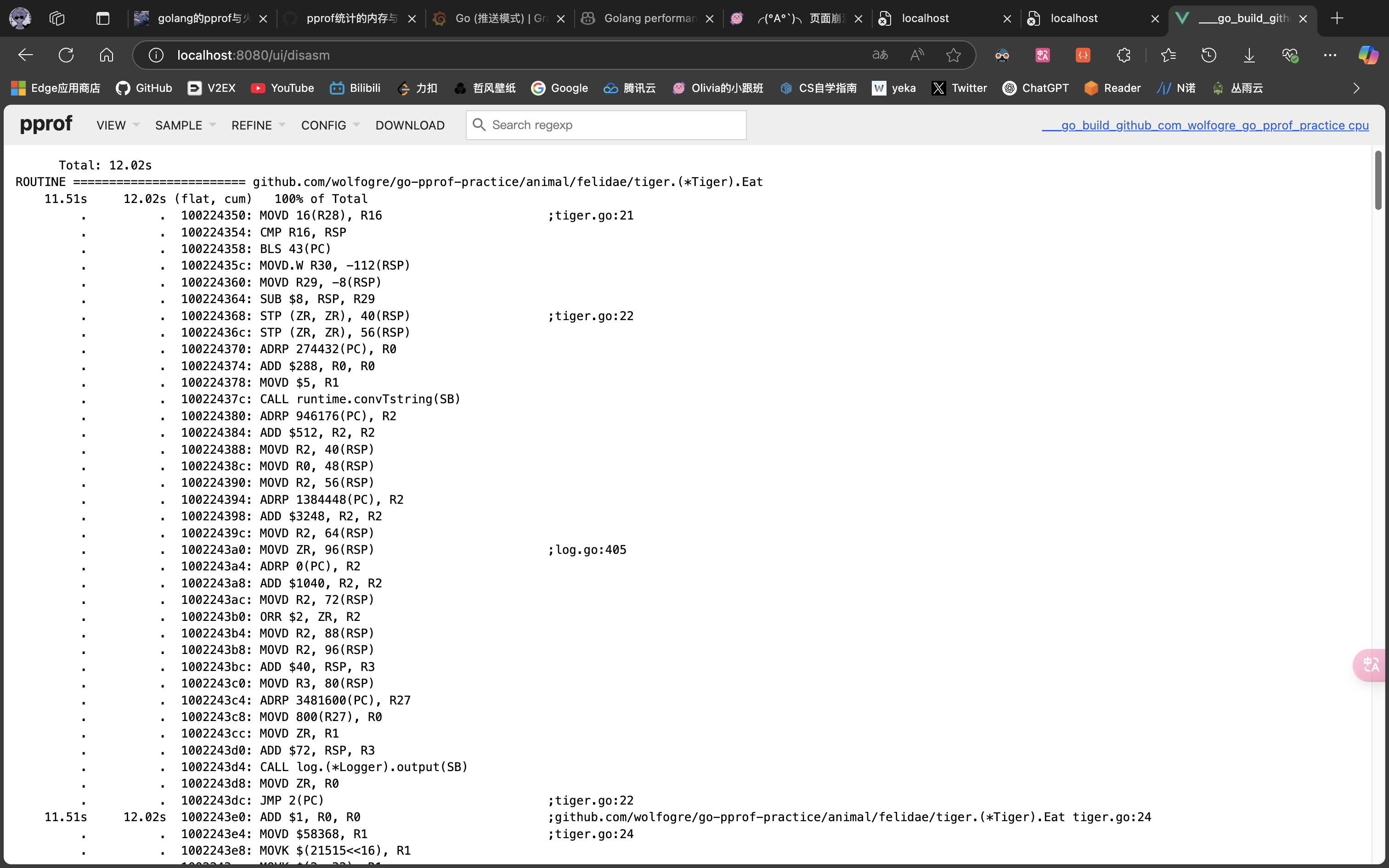
- Disassemble
7、数据分析实战
7.1、排查套
7.1.1、套路1
这里先说一下排查套路。
第一步:进入排除对应的gdb交互。
1 | go tool pprof http://localhost:6060/debug/pprof/{填上你想查看的内容}?seconds=10 |
- seconds=10, 采样间隔时间数字
内容关键字:
| 类型 | 描述 |
|---|---|
| allocs | 内存分配情况的采样信息 |
| blocks | 阻塞操作情况的采样信息 |
| cmdline | 显示程序启动命令参数及其参数 |
| goroutine | 显示当前所有协程的堆栈信息 |
| heap | 堆上的内存分配情况的采样信息 |
| mutex | 锁竞争情况的采样信息 |
| profile | cpu占用情况的采样信息,点击会下载文件 |
| threadcreate | 系统线程创建情况的采样信息 |
| trace | 程序运行跟踪信息 |
第二步:三联招,top->list FuncName->web
通过占用比分析,查看具体代码行数,看大图确认。
第三步:解决问题。
(细心的同学可能会发现没有对trace进行分析,这个请期待《一看就懂系列之Golang的trace》)
7.1.2、套路2-推荐
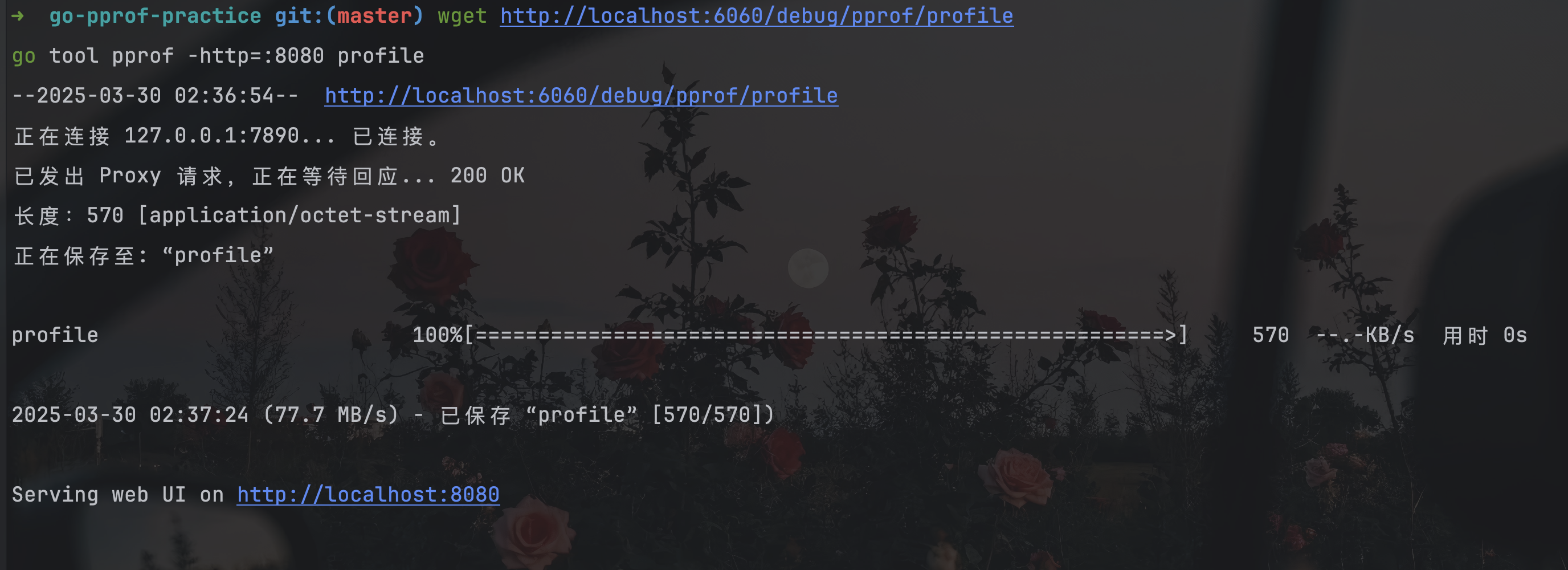
将其重新运行起来,然后在其它窗口执行下述命令:
1 | wget http://127.0.0.1:6060/debug/pprof/profile |
默认需要等待 30 秒,执行完毕后可在当前目录下发现采集的文件 profile,针对可视化界面我们有两种方式可进行下一步分析:该命令将在所指定的端口号运行一个 PProf 的分析用的站点。
1 | go tool pprof -http=:6001 profile |
7.2、背景说明
本章节使用WOLFOGRE的文章进行实践。
1 | git clone github.com/wolfogre/go-pprof-practice |
运行后注意查看一下资源是否吃紧,机器是否还能扛得住,坚持一分钟,如果确认没问题,咱们再进行下一步。
7.3、排查 CPU 占用过高
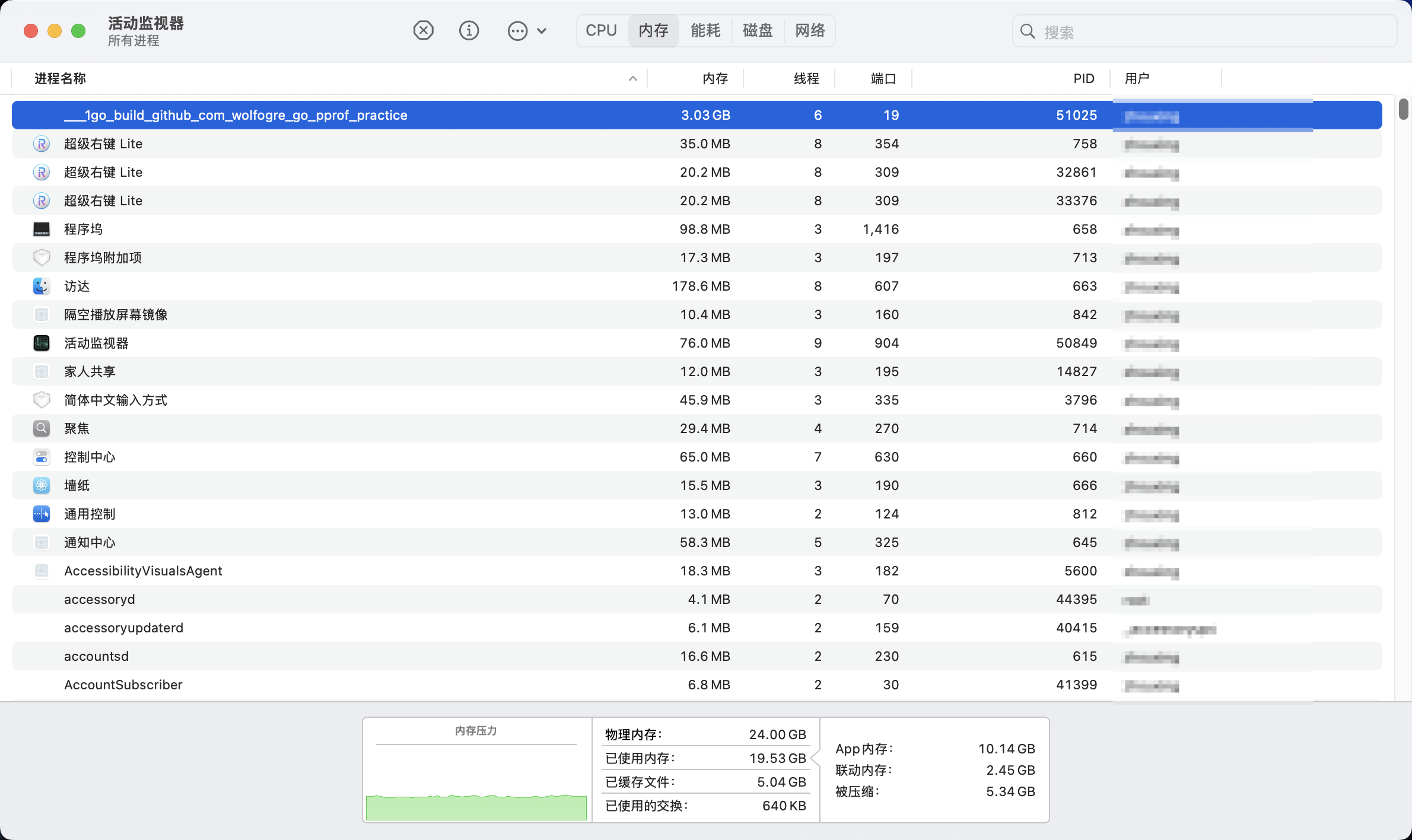
我们首先通过活动监视器(或任务管理器、top 命令,取决于你的操作系统和你的喜好),查看一下炸弹程序的 CPU 占用:
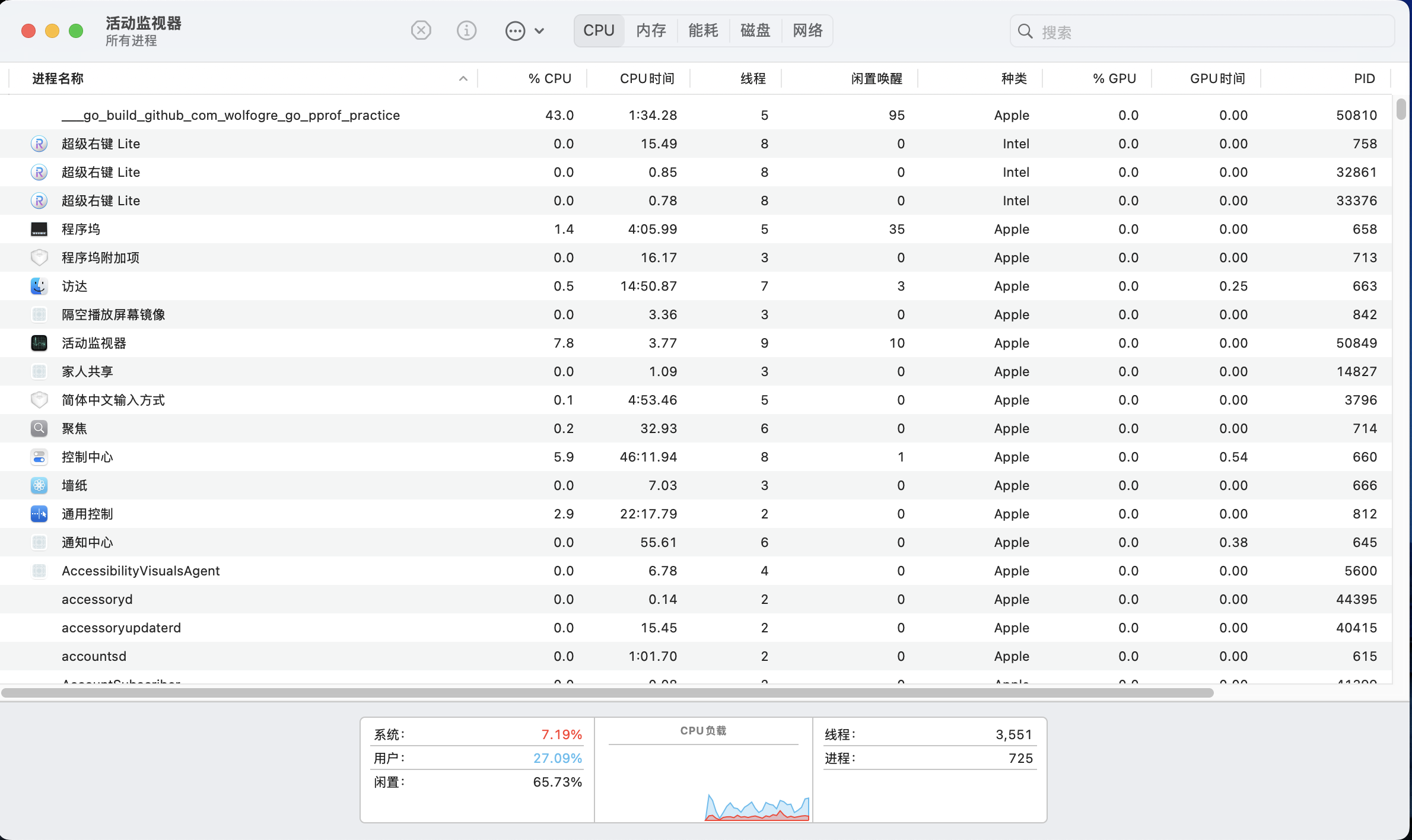
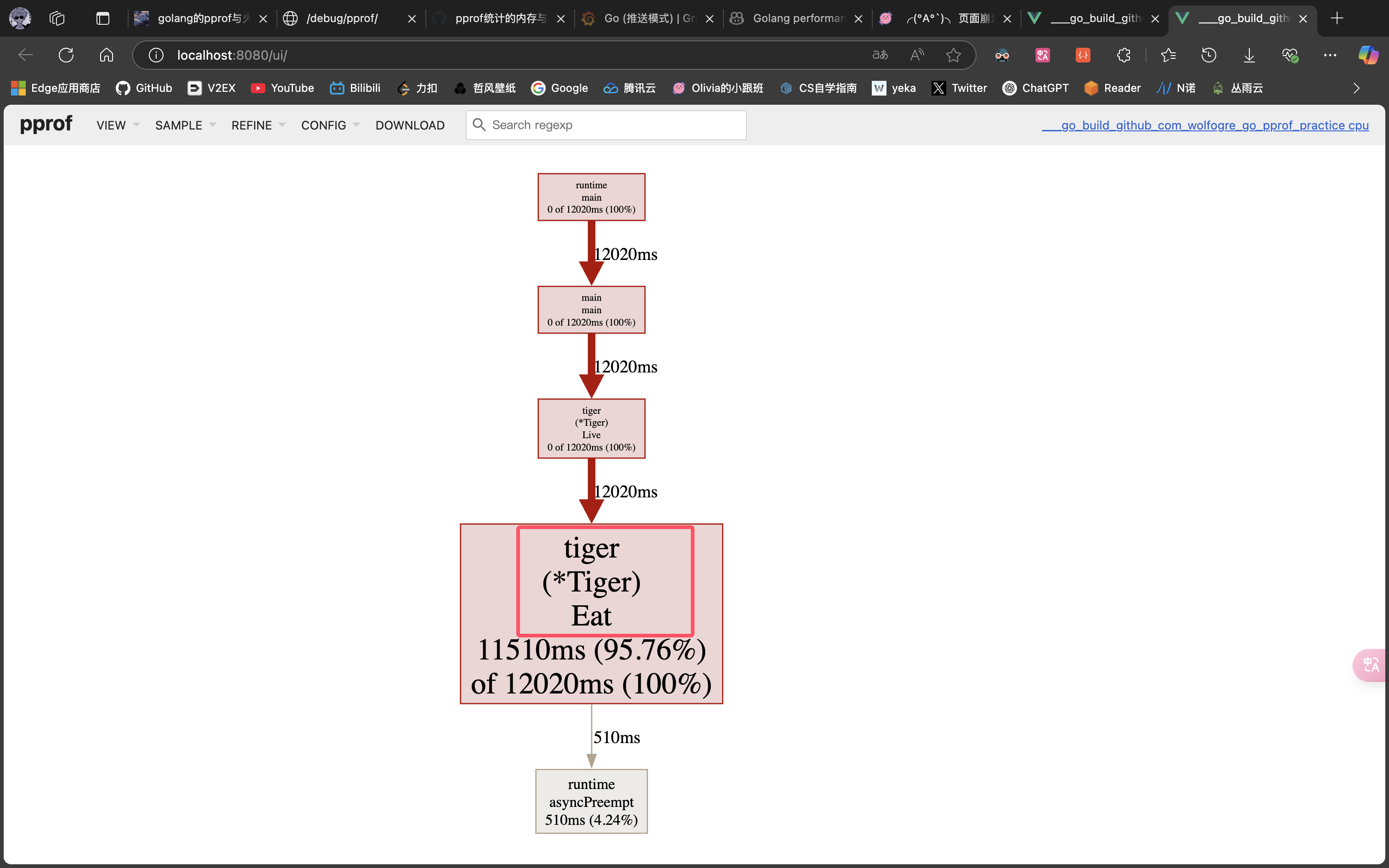
很明显,CPU 占用过高是 github.com/wolfogre/go-pprof-practice/animal/felidae/tiger.(*Tiger).Eat 造成的。
可以看到,是第 24 行那个一百亿次空循环占用了大量 CPU 时间,至此,问题定位成功!
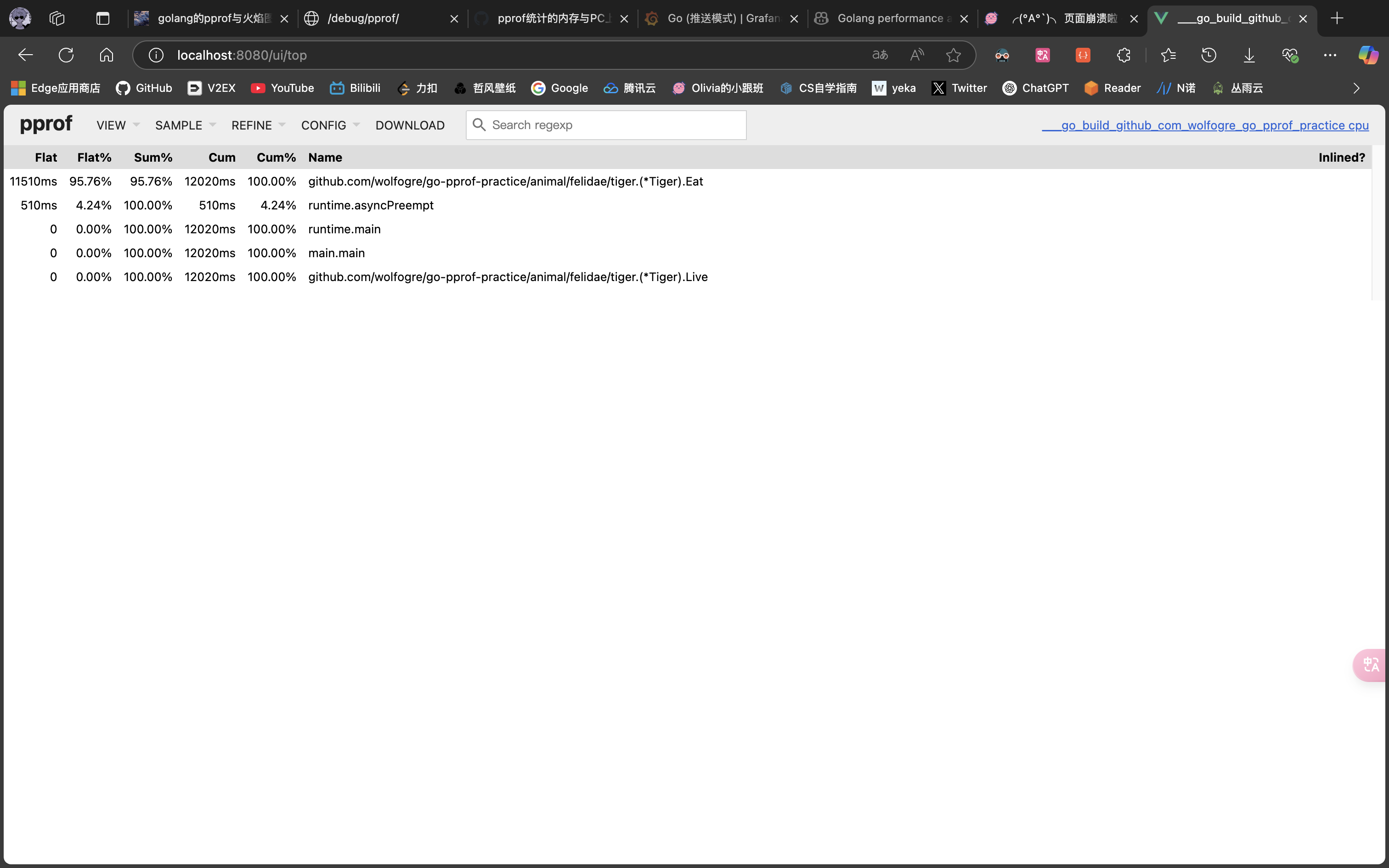
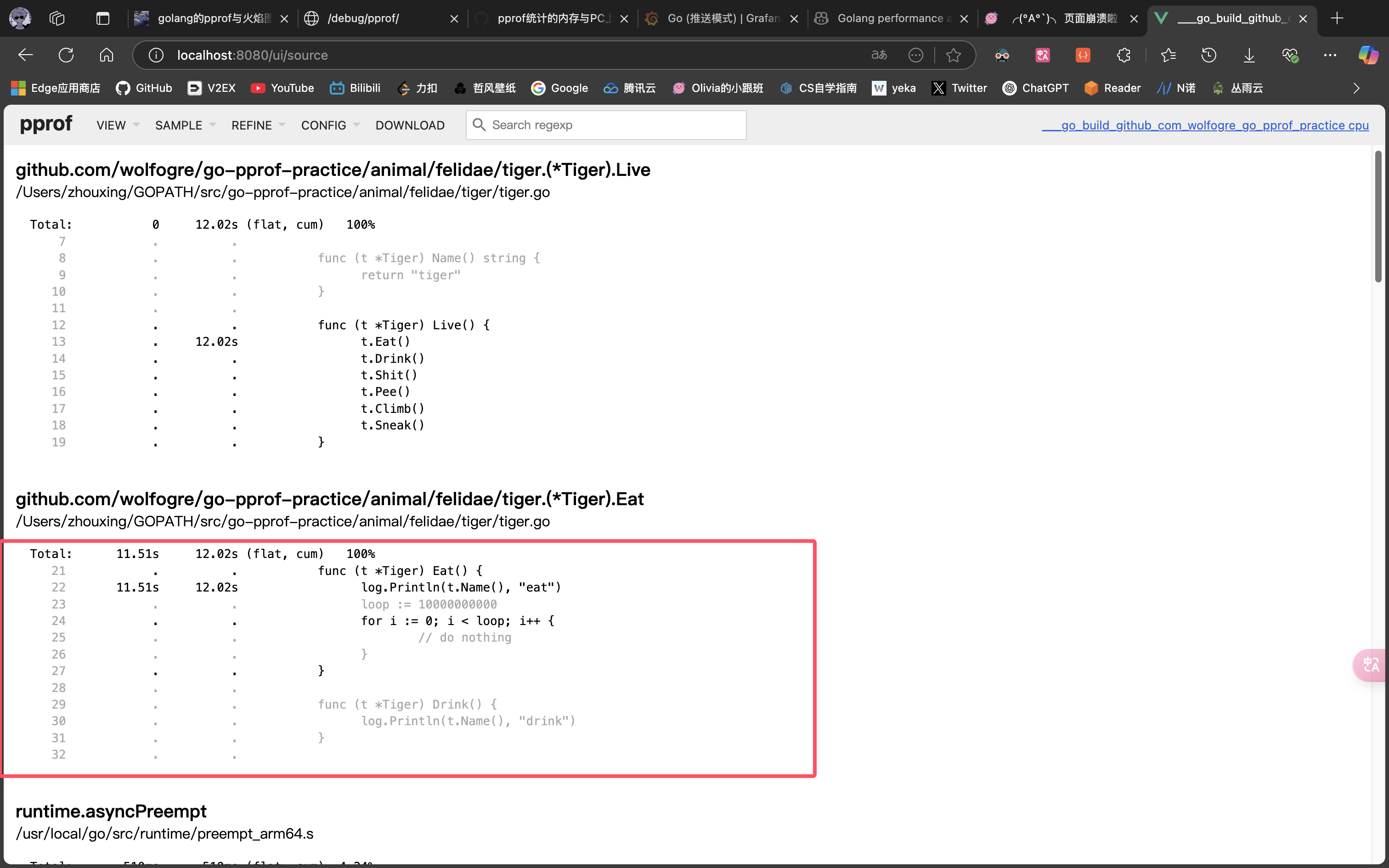
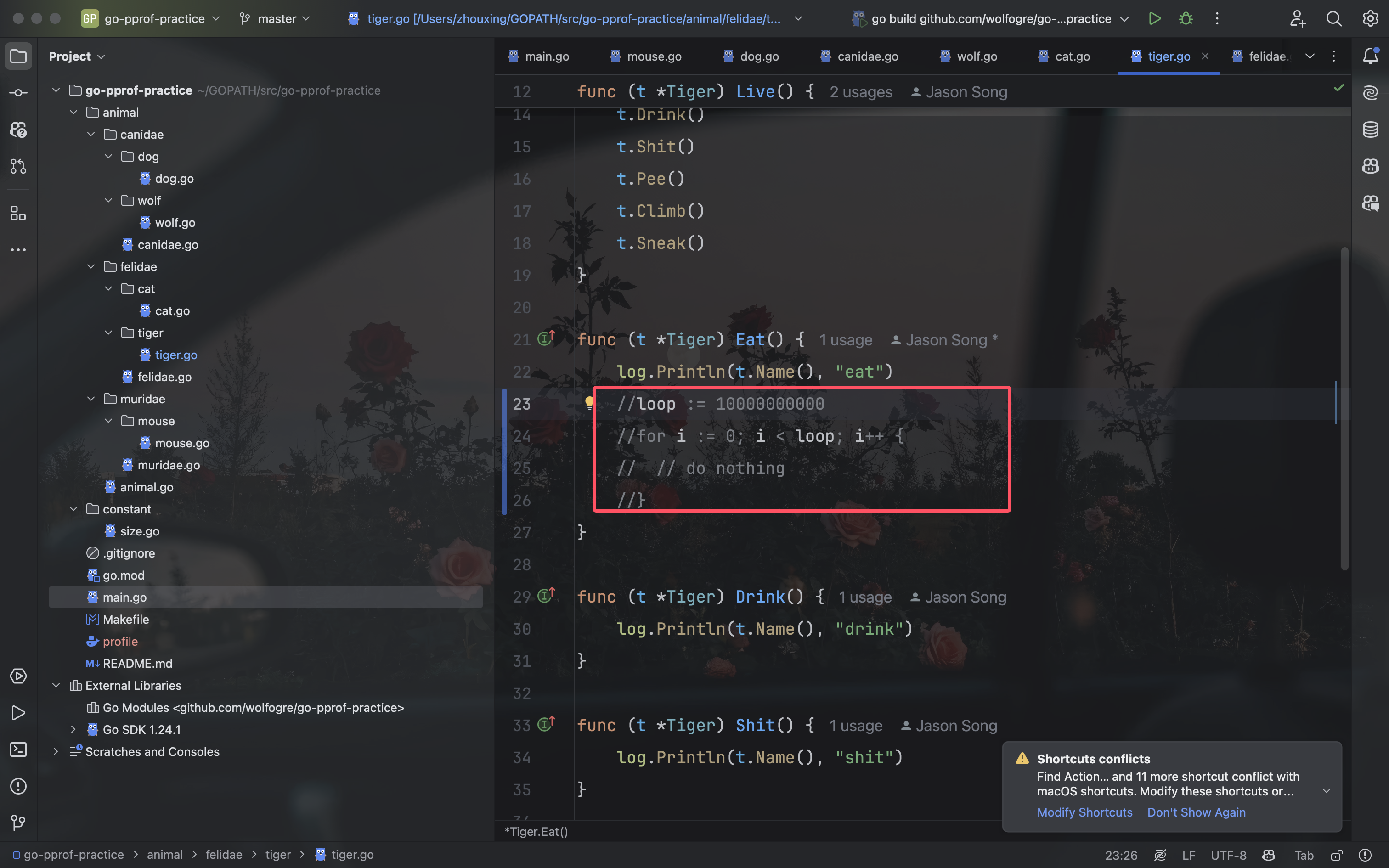
之后修复问题的的方法都是注释掉相关的代码,不再赘述。你可能觉得这很粗暴,但要知道,这个实验的重点是如何使用 pprof 定位问题,我们不需要花太多时间在改代码上。
7.4、排查内存占用过高
重新编译炸弹程序,再次运行,可以看到 CPU 占用率已经下来了,但是内存的占用率仍然很高:
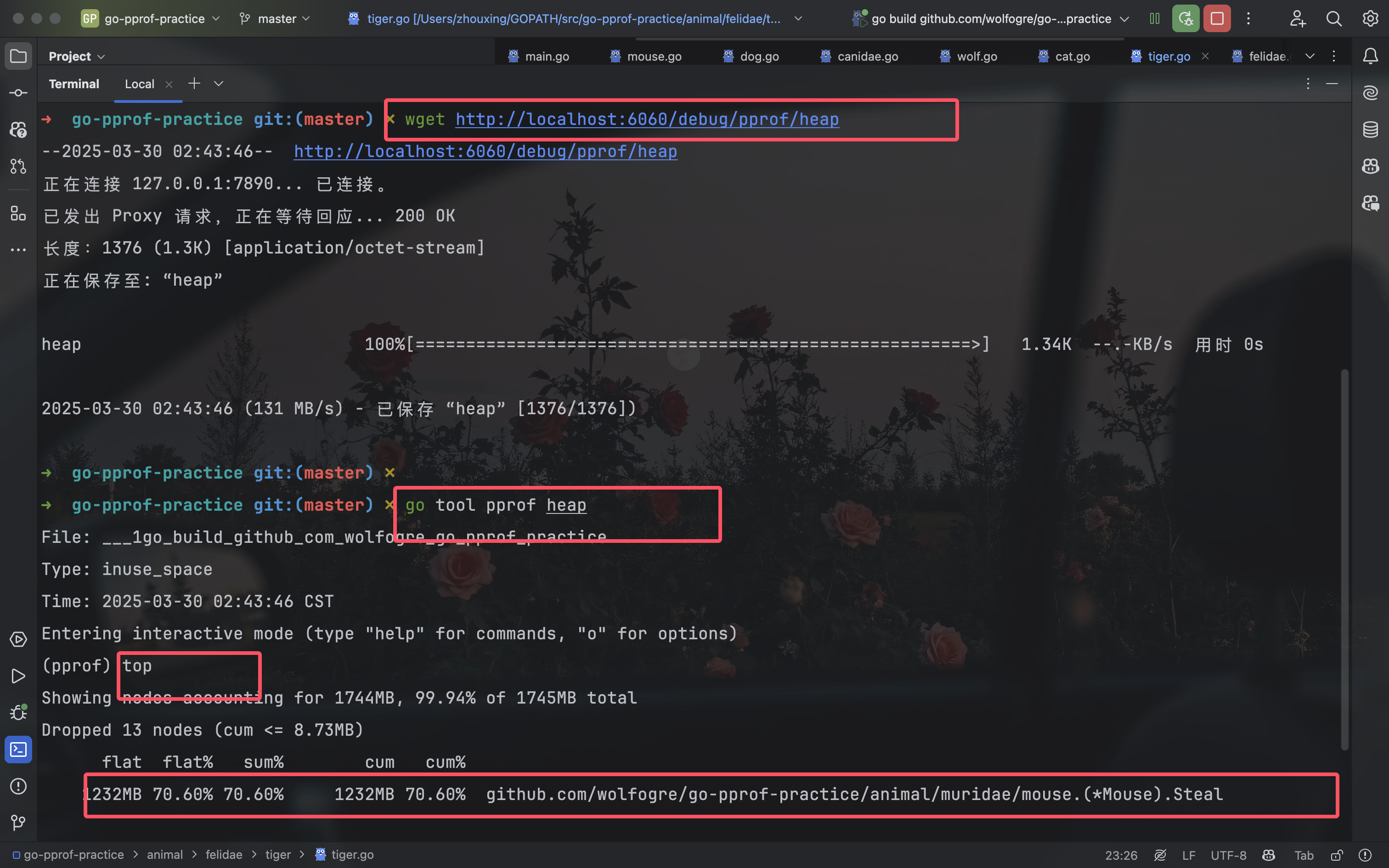
可以看到这次出问题的地方在 github.com/wolfogre/go-pprof-practice/animal/muridae/mouse.(*Mouse).Steal注释代码就可以了
go tool pprof -inuse_space http://localhost:6060/debug/pprof/heap
| 选项名 | 作用 |
|---|---|
| alloc_objects | 分析应用程序的内存临时分配情况 |
| alloc_space | 查看每个函数分配的内存空间大小 |
| inuse_space | 分析应用程序的常驻内存占用情况 |
| inuse_objects | 查看每个函数所分配的对象数量 |
7.5 排查频繁内存回收(同4.2.3)
你应该知道,频繁的 GC 对 golang 程序性能的影响也是非常严重的。虽然现在这个炸弹程序内存使用量并不高,但这会不会是频繁 GC 之后的假象呢?为了获取程序运行过程中 GC 日志,我们需要先退出炸弹程序,再在重新启动前赋予一个环境变量,同时为了避免其他日志的干扰,使用 grep 筛选出 GC 日志查看:
1 | GODEBUG=gctrace=1 ./go-pprof-practice | grep gc |
日志输出如下:
可以看到,GC 差不多每 3 秒就发生一次,且每次 GC 都会从 16MB 清理到几乎 0MB,说明程序在不断的申请内存再释放,这是高性能 golang 程序所不允许的。如果你希望进一步了解 golang 的 GC 日志可以查看《如何监控 golang 程序的垃圾回收》,为保证实验节奏,这里不做展开。所以接下来使用 pprof 排查时,我们在乎的不是什么地方在占用大量内存,而是什么地方在不停地申请内存,这两者是有区别的。由于内存的申请与释放频度是需要一段时间来统计的,所有我们保证炸弹程序已经运行了几分钟之后,再运行命令:
1 | go tool pprof http://localhost:6060/debug/pprof/allocs |
同样使用 top、list、web 大法:
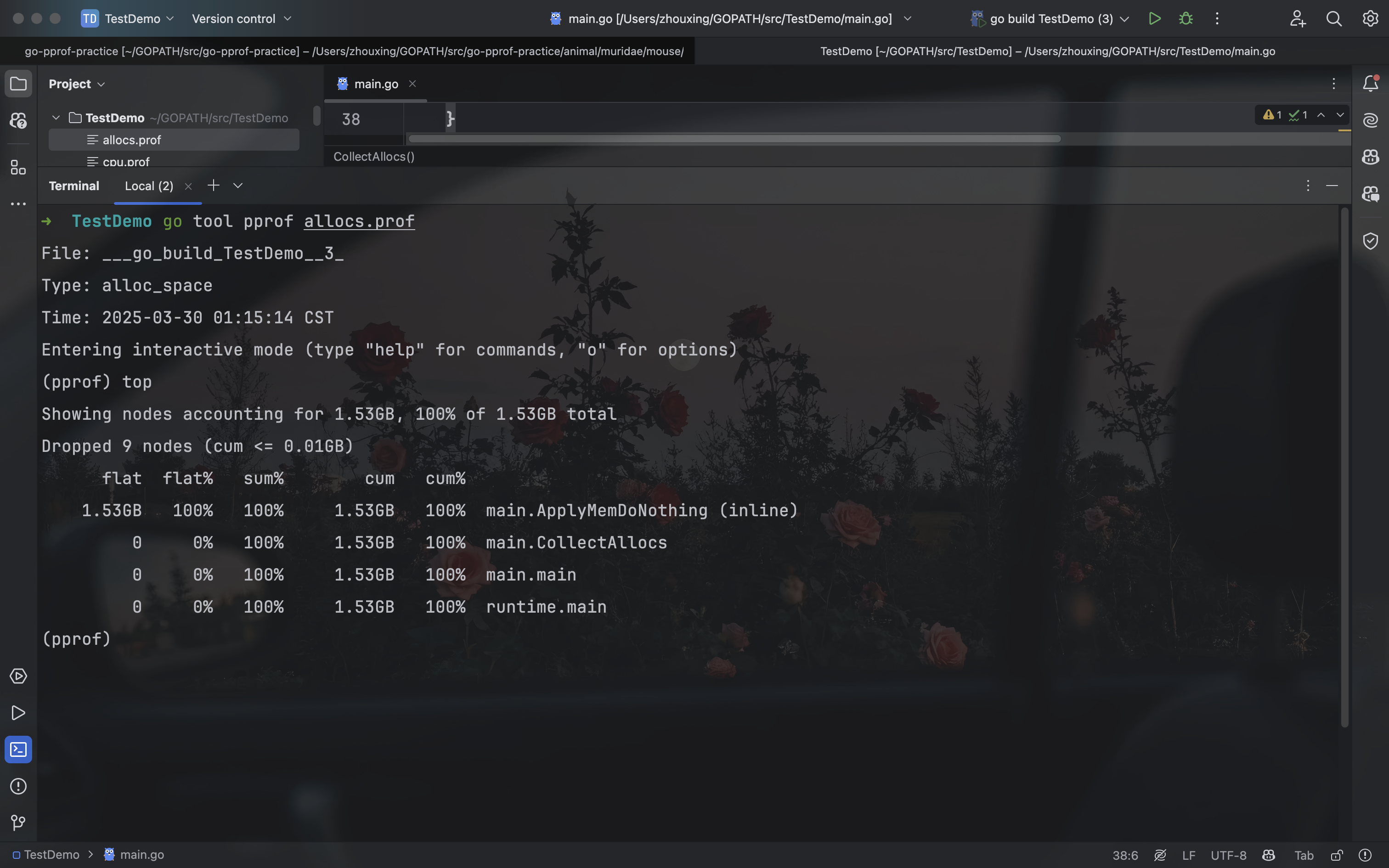
可以看到 github.com/wolfogre/go-pprof-practice/animal/canidae/dog.(*Dog).Run 会进行无意义的内存申请,而这个函数又会被频繁调用,这才导致程序不停地进行 GC:
1 | func (d *Dog) Run() { |
这里有个小插曲,你可尝试一下将 16 * constant.Mi 修改成一个较小的值,重新编译运行,会发现并不会引起频繁 GC,原因是在 golang 里,对象是使用堆内存还是栈内存,由编译器进行逃逸分析并决定,如果对象不会逃逸,便可在使用栈内存,但总有意外,就是对象的尺寸过大时,便不得不使用堆内存。所以这里设置申请 16 MiB 的内存就是为了避免编译器直接在栈上分配,如果那样得话就不会涉及到 GC 了。我们同样注释掉问题代码,重新编译执行,可以看到这一次,程序的 GC 频度要低很多,以至于短时间内都看不到 GC 日志了。
7.6、排查协程泄露
由于 golang 自带内存回收,所以一般不会发生内存泄露。但凡事都有例外,在 golang 中,协程本身是可能泄露的,或者叫协程失控,进而导致内存泄露。我们在浏览器里可以看到,此时程序的协程数已经多达 60 条:
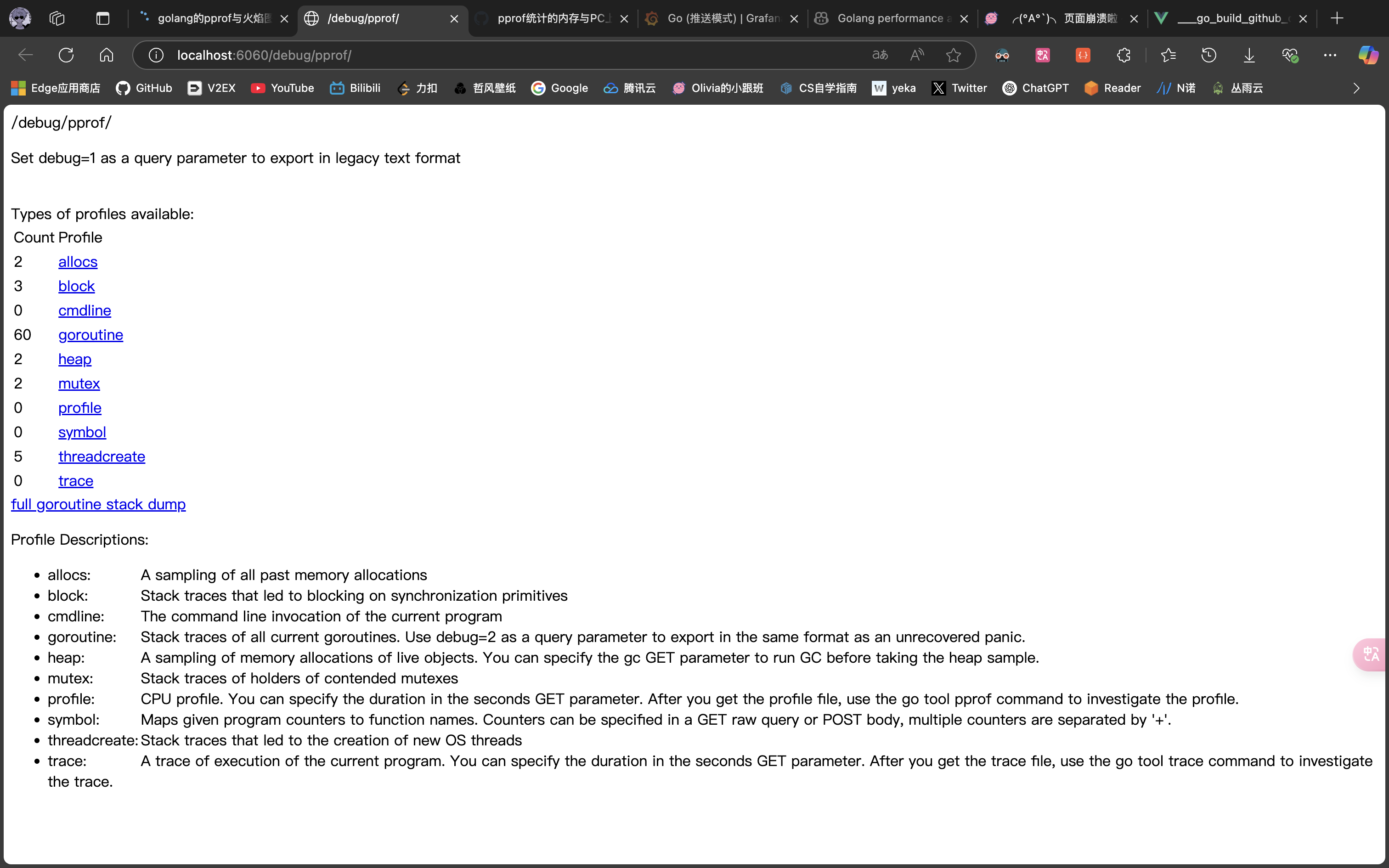
1 | wget http://localhost:6060/debug/pprof/goroutine |
然后查看代码,可以看到,Drink 函数每次回释放 10 个协程出去,每个协程会睡眠 30 秒再退出,而 Drink 函数又会被反复调用,这才导致大量协程泄露,试想一下,如果释放出的协程会永久阻塞,那么泄露的协程数便会持续增加,内存的占用也会持续增加,那迟早是会被操作系统杀死的。我们注释掉问题代码,重新编译运行可以看到,协程数已经降到 9 条了:
7.7、排查锁的争用
到目前为止,我们已经解决这个炸弹程序的所有资源占用问题,但是事情还没有完,我们需要进一步排查那些会导致程序运行慢的性能问题,这些问题可能并不会导致资源占用,但会让程序效率低下,这同样是高性能程序所忌讳的。
我们首先想到的就是程序中是否有不合理的锁的争用,我们倒一倒,回头看看上一张图,虽然协程数已经降到 4 条,但还显示有一个 mutex 存在争用问题。
相信到这里,你已经触类旁通了,无需多言,开整。
1 | wget http://localhost:6060/debug/pprof/mutex |
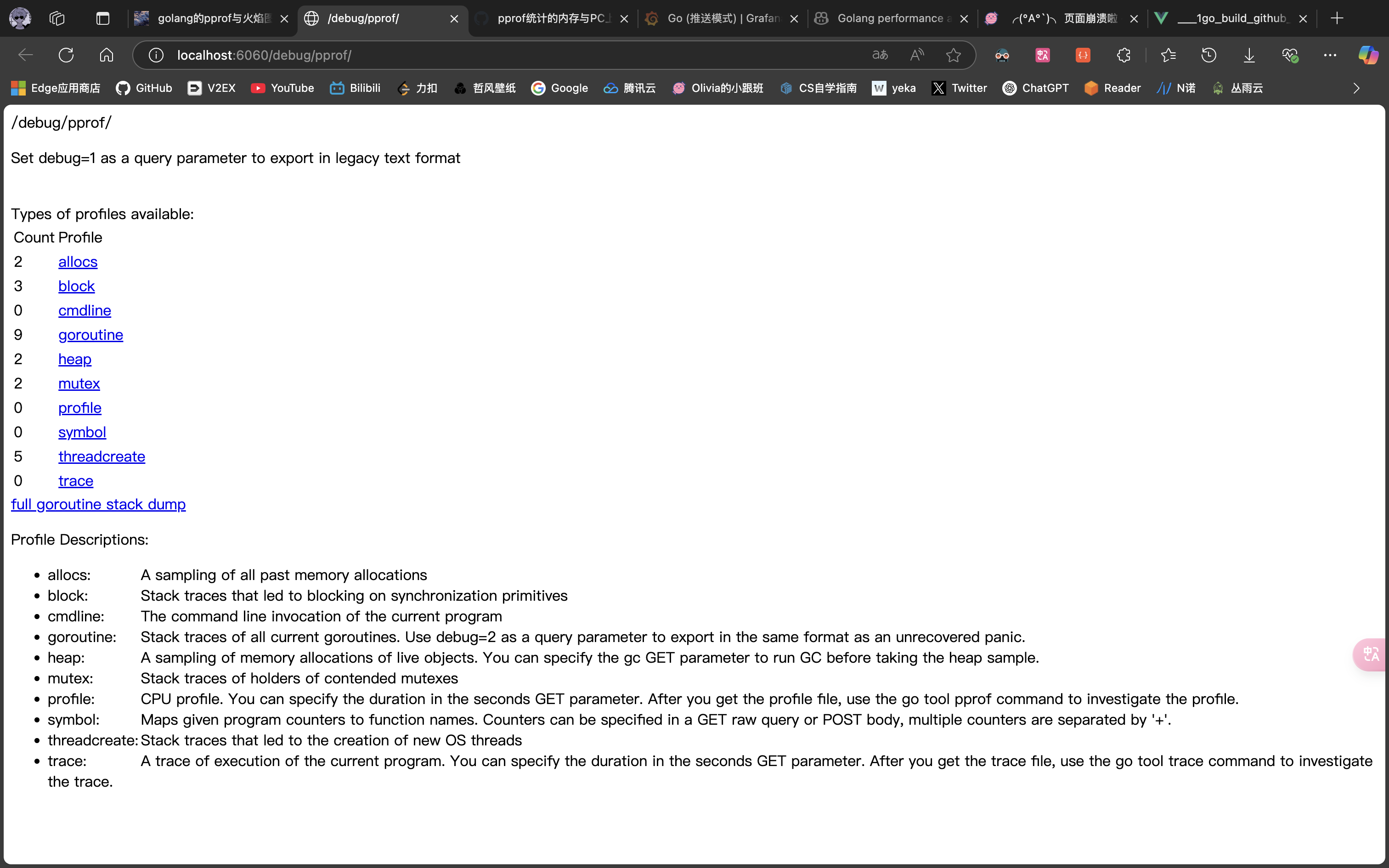
可以看出来这问题出在 github.com/wolfogre/go-pprof-practice/animal/canidae/wolf.(*Wolf).Howl。但要知道,在代码中使用锁是无可非议的,并不是所有的锁都会被标记有问题,我们看看这个有问题的锁那儿触雷了。
可以从代码看到,这个锁由主协程 Lock,并启动子协程去 Unlock,主协程会阻塞在第二次 Lock 这儿等待子协程完成任务,但由于子协程足足睡眠了一秒,导致主协程等待这个锁释放足足等了一秒钟。虽然这可能是实际的业务需要,逻辑上说得通,并不一定真的是性能瓶颈,但既然它出现在我写的“炸弹”里,就肯定不是什么“业务需要”啦。所以,我们注释掉这段问题代码,重新编译执行,继续。
7.8、排查阻塞操作
好了,我们开始排查最后一个问题。
在程序中,除了锁的争用会导致阻塞之外,很多逻辑都会导致阻塞。
1 | wget http://localhost:6060/debug/pprof/block |
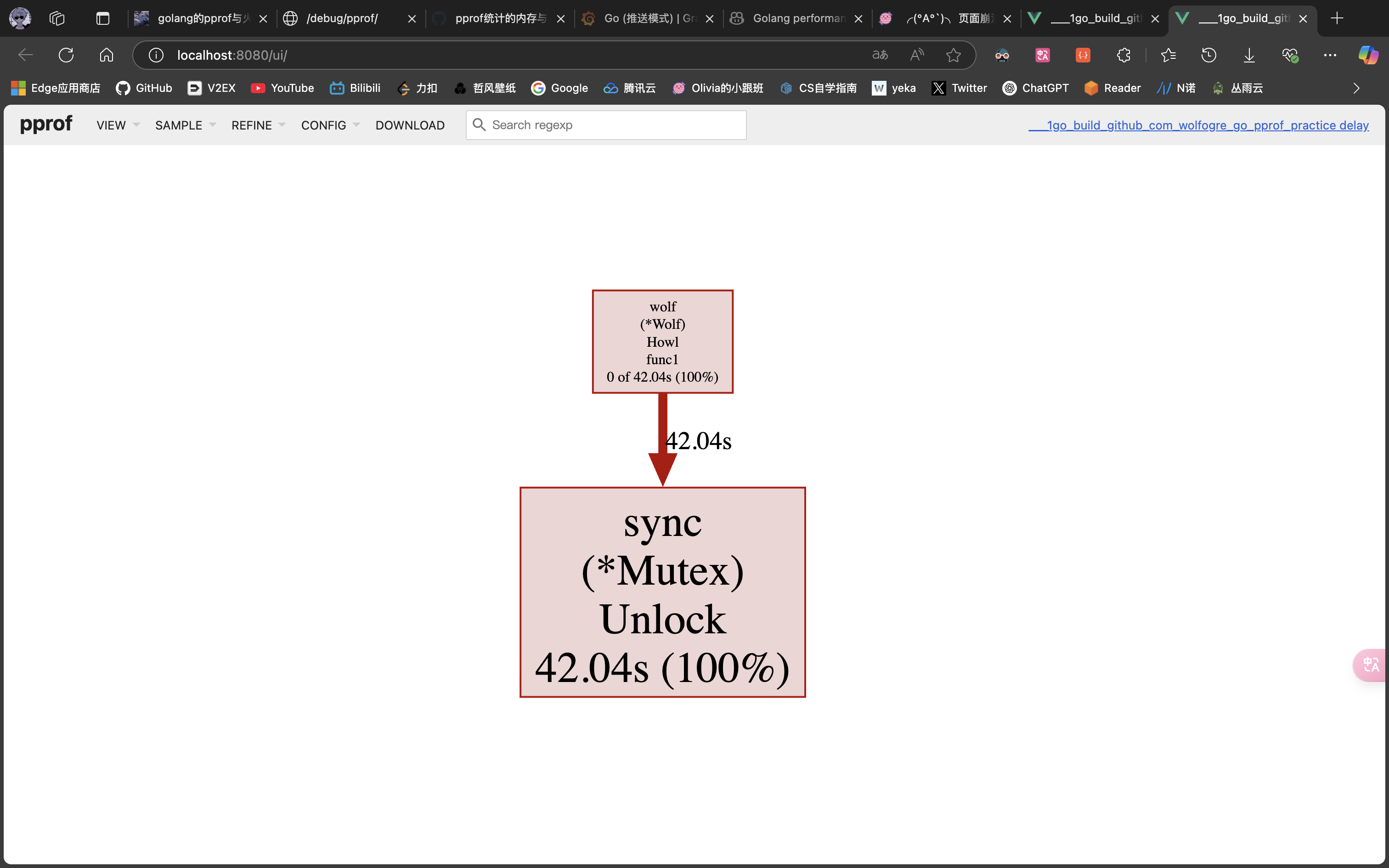
可以看到,阻塞操作位于 github.com/wolfogre/go-pprof-practice/animal/felidae/cat.(*Cat).Pee:
你应该可以看懂,不同于睡眠一秒,这里是从一个 channel 里读数据时,发生了阻塞,直到这个 channel 在一秒后才有数据读出,这就导致程序阻塞了一秒而非睡眠了一秒。
8、代码优化建议
以下是一些从其它项目借鉴或者自己总结的实践经验,它们只是建议,而不是准则,实际项目中应该以性能分析数据来作为优化的参考,避免过早优化。
- 对频繁分配的小对象,使用 sync.Pool 对象池避免分配
- 自动化的 DeepCopy 是非常耗时的,其中涉及到反射,内存分配,容器(如 map)扩展等,大概比手动拷贝慢一个数量级
- 用 atomic.Load/StoreXXX,atomic.Value, sync.Map 等代替 Mutex。(优先级递减)
- 使用高效的第三方库,如用fasthttp替代 net/http
- 在开发环境加上
-race编译选项进行竞态检查 - 在开发环境开启 net/http/pprof,方便实时 pprof
- 将所有外部IO(网络IO,磁盘IO)做成异步
9、pyroscope
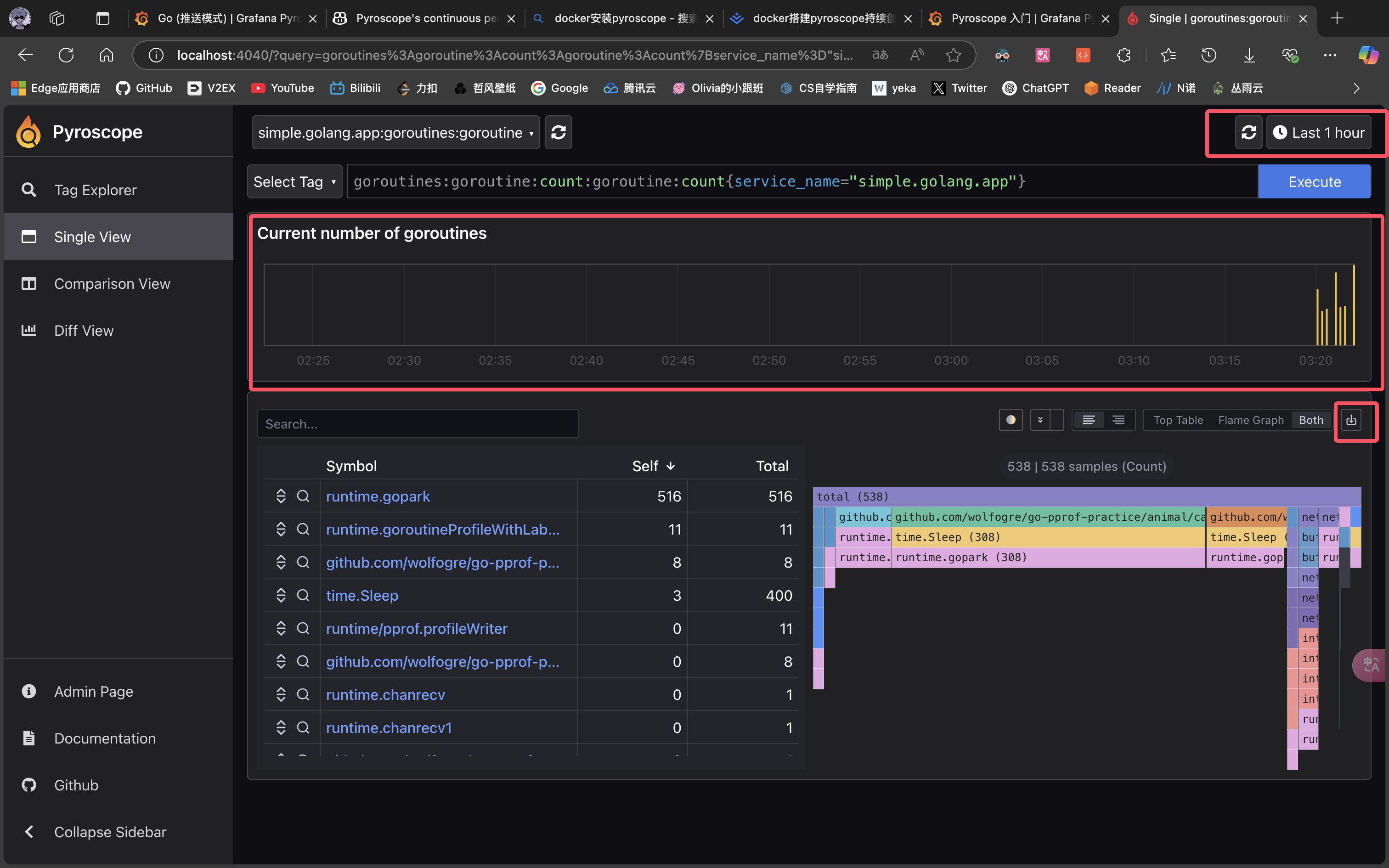
为什么要用它?当你半夜酣睡时,即使系统出现了 CPU 飙升、OOM 或协程泄露,第二天仍然可以通过 Pyroscope 查看完整的性能分析数据,这就是它的一个重要价值所在。
简单使用:
1 | docker network create pyroscope-demo |
1 | go get github.com/grafana/pyroscope-go |
1 | package main |
参考文章
[WOLFOGRE’S BLOG]golang pprof 实战
pprof统计的内存与PC上显示的内存不符合 · Issue #1 · wolfogre/go-pprof-practice
- 标题: golang的pprof与火焰图实战
- 作者: 纸鸢
- 创建于 : 2025-01-19 22:43:05
- 更新于 : 2025-03-30 03:23:30
- 链接: https://www.youandgentleness.cn/2025/01/19/golang的pprof与火焰图实战/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。