Go服务开发Tips
1、如何性能优化
五大步骤:定目标、找瓶颈点、分析瓶颈原因、性能优化、验证目标
2、优化性能三大利器
- pprof
- cpu采样用于确定程序中哪些函数或代码片段在运行时消耗了大量的CPU 时间,帮助定位CPU性能瓶颈。
- allocs采样侧重于定位那些频繁进行内存分配的函数。
- heap采样用于查看存活对象的内存分配情况,侧重于定位内存泄漏问题。
- benchmark
- trace

3、代码优化
- 当用map构造集合时,我们可以将value类型设置为空结构体类型,空结构体类型不占用内存空间,这样就能帮我们降低内存资源消耗。
- 当创建map和切片对象时,如果我们可以提前确定容器容量,就可以传入make函数中,从而避免往集合中添加数据时触发扩容迁移,达到降低内存和CPU资源消耗的目的。
- 高性能字符串拼接技巧。当我们代码有大量字符串拼接操作时,可以使用 strings.Builder 类型,并利用它的内存预分配功能做字符串拼接。
- 高性能整型转字符串技巧。当我们代码有大量整型转字符串操作时,可以用 strconv 库做转换,避免使用fmt.Sprint函数的反射和格式化资源消耗。
- 高性能字符串转字节切片技巧。当我们代码有大量字符串转字节切片操作时,可以用 unsafe 包,通过字符串和字节切片底层数组空间共用,实现高性能转换。并且,也可以用unsafe包将字节切片转换为字符串。(补充:现在go1.22版本已经实现相互零拷贝)
- 当我们对结构体数组或切片做循环遍历时,基于性能上的考虑,建议优先使用下标遍历的方式,而不提倡使用for range值遍历的方式。
- 对于数据处理的优化,咱们还有一种常用的思路,当官方库没有性能更高的实现方式时,可以使用性能更高的第三方库。比如当我们需要进行JSON序列化和反序列化操作时,可以使用考虑使用 sonic库。
- 当我们编写的代码中需要频繁创建相同类型的临时对象时,可以使用 sync.Pool 对象池,实现临时对象复用,从而减少 Go中的内存分配和GC开销。
- 当我们的代码需要频繁地创建协程,这时候使用协程池就很关键了。通过协程复用,我们可以降低协程创建的开销。同时,协程池能限制同时运行的协程的最大数目,从而避免同时有太多协程,导致频繁进行协程调度。
4、并发等待技巧
- WaitGroup 类型。当我们手头有一个规模较大的任务时,为了提高执行效率,我们可以巧妙地将其拆分成多个子任务,然后让这些子任务并发运行。而此时,如果我们还需要等待所有子任务都顺利执行完毕,那么 WaitGroup 类型就该闪亮登场啦,它能够精准地满足这一需求。
- errgroup 包。实际上,errgroup 包可以看作是对 WaitGroup 类型的升级与封装。当我们在实际开发中,不仅需要并发运行任务,还得周全地考虑对可能出现的错误进行妥善处理、能够灵活地取消任务以及精准地控制最大协程数等复杂需求,这时errgroup 包无疑就是我们的最佳选择。
5、锁的使用
- 当对数据的写操作较多或者读操作不频繁时,可以使用互斥锁保证并发访问的安全性;
- 当读操作远远多于写操作时,可以使用读写锁,允许多个协程同时进行读操作,而在写操作时进行独占式访问,这样可以提高并发读取的性能;
- 当大量数据存储在map中,并且协程对map的访问相对均匀地分布在不同的键上时,可以考虑使用分段锁提高性能。具体是通过将map分成多个段,每个段有自己的锁,降低锁粒度,从而提升并发性能。
- 当需要对共享对象进行原子操作时,可以利用atomic包无锁编程,避免加锁操作,从而提升性能。
6、大规模数据缓存如何设计数据结构
针对大规模数据缓存的场景,我们在数据结构设计上要考虑的技术点有两个。
- 如何实现并发安全的map类型。
- 如何减少甚至避免因大规模数据缓存导致的GC开销。
因为sync.map的缺点有如下几点,所以一般我们使用分段锁map:
- 由于有两个map,因此占用内存会比较高。
- 更适用于读多写少的场景,当由于写比较多或者本地缓存没有全量数据时,会导致读map经常读不到数据,而需要加锁再读一次,从而导致读性能退化。
- 当数据量比较大时,如果写入触发读map向写map拷贝,会导致较大的性能开销。
当map中缓存的数据比较多时,为了避免GC开销,我们可以将map中的key-value类型设计成非指针类型且大小不超过128字节,从而避免GC扫描。
7、IO多路复用底层
Golang底层使用的epoll,存在两个问题。针对这两个问题,我以字节开源的高
性能网络库netpoll为例,看它是如何解决这两个问题的。
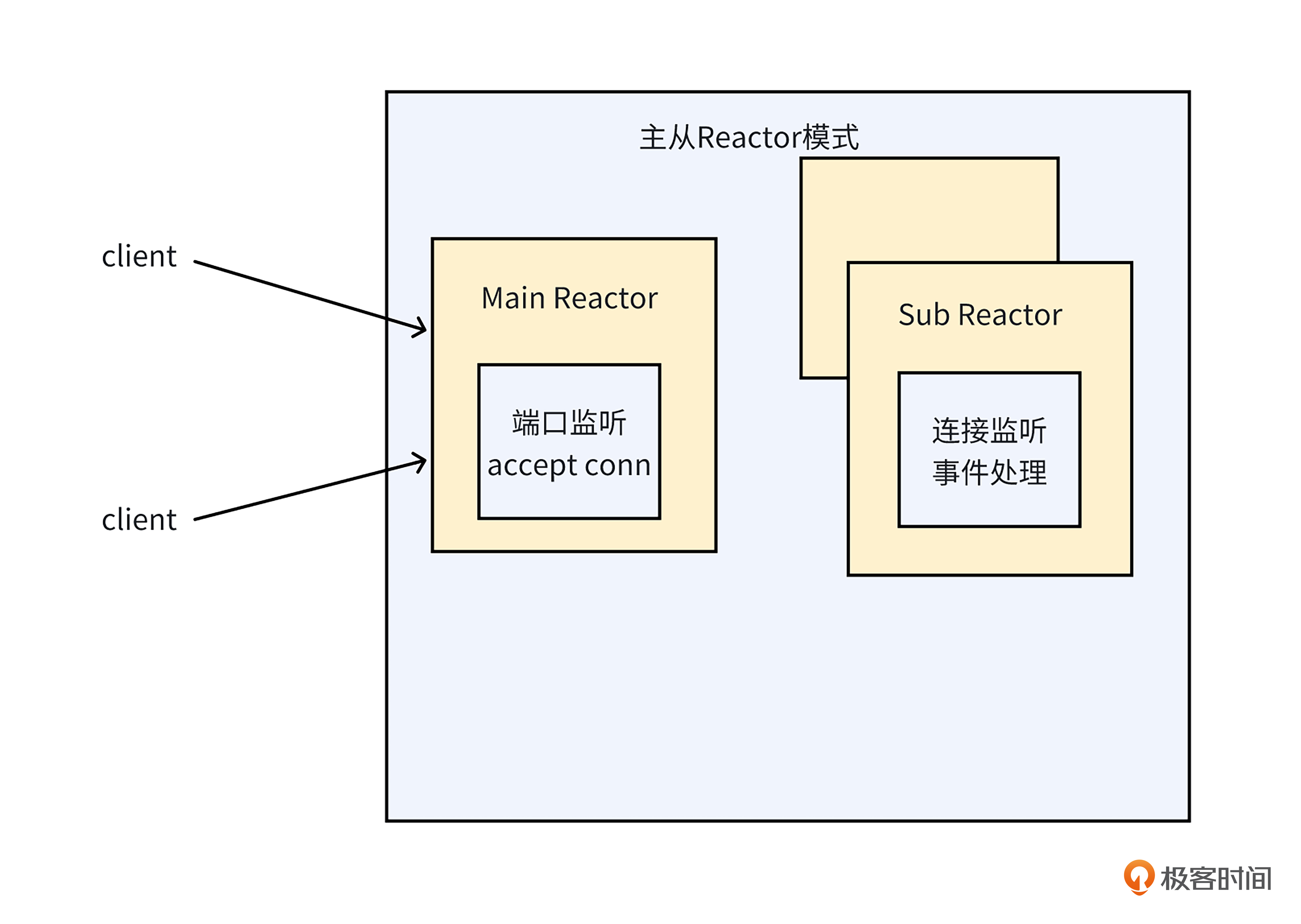
针对高并发场景循环处理的事件过多的问题,就像下面的图一样,netpoll采用了主从多Reactor的模式。也就是由多个协程监听多个epoll池,每个epoll池放一部分需要监听的文件描述符(fd)。主Reactor监听连接事件,从Reactor监听读写等网络事件。

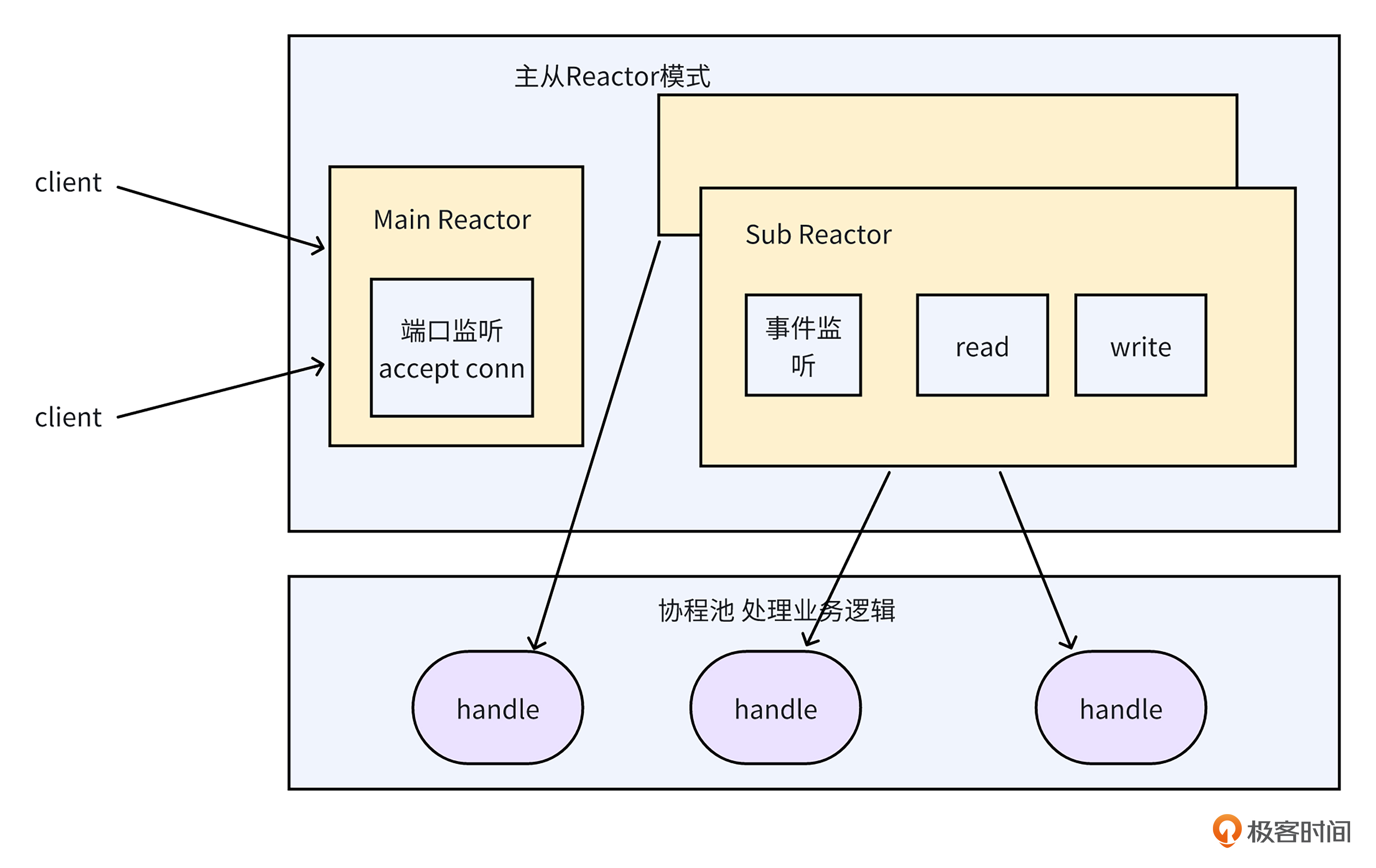
针对net库读写未就绪,导致协程阻塞问题,就像下面的图一样,netpoll由从Reactor完成内核和程序之间的数据复制,协程池中的协程只负责异步对业务逻辑进行处理,不再需要阻塞等待网络IO事件就绪和数据复制,从而避免了大量协程因网络IO而被阻塞的问题。
8、网络通信延时
跨机通信优化:为了降低网络传输延时,我们需要让服务调用的物理距离更近一点,尽量不跨地域、不跨机房调用。
亲和性部署方案:把上下游服务部署到一台物理机里,优先进行同机调用,从而消除网络传输开销。
合并编译方案:将Server编译成SDK,并将Client对Server的RPC调用,变成本地SDK的函数调用,从而消除服务调用的编解码开销。

9、架构层面来优化数据库的读写性能
高并发读写场景:
- 首先是读写分离架构。当我们数据库读QPS过高时,可以通过读写分离架构,增加从库来提升数据库集群的读QPS。
- 其次是分表架构。当我们单表数据行数太多,导致读性能下降时,可以用分表架构,将一张表拆成多张小表,从而提升读性能。
- 最后是分库架构。当我们数据库写入TPS过高时,可以用分库架构,通过增加多个主库,分散单库的写压力,从而提升数据库整体的写TPS上限。
10、如何解决热Key问题
- 首先是业务服务本地缓存全量数据的方案。要是数据量不大,我们可以直接在服务本地内存把所有数据都缓存起来,这样能大幅度降低热Key问题导致的Redis访问压力。
- 然后是业务服务本地只缓存热Key数据的方案。当服务不能缓存全部数据时,我们可以接入热 Key 探测框架,只把那些被频繁访问的热 Key 数据存到本地,节省内存之外还能保证热 Key 的快速读取。
- 之后是Redis读写分离架构方案。要是不想让业务层变得复杂,我们可以采取读写分离架构,给每个 Redis Server 都加上从库,让从库去应对热 Key 的高频率读取,分担压力。
- 最后是Proxy热Key承载方案。由于读写分离架构会增加Redis资源成本,所以在Redis提供了热Key承载方案的条件下,我们可以优先用Proxy热Key承载方案,这样既能解决热 Key 问题,又能控制成本。
补充:signlefight机制也可以解决
11、如何解决大Key问题
首先是基于PB序列化的数据压缩方案。在将数据存储到Redis时,我们很多时候会使用JSON格式。通过改用PB序列化,我们可以避免不必要的数据写入,从而有效减少数据体积,预防大Key问题的发生。
其次是基于版本号机制的大Key拆分方案。在数据经过压缩后,如果它的大小仍然超出了大Key的标准,我们就可以采用这一方案。通过将数据拆分成多个部分,并为每个部分添加版本号作为子Key,我们可以有效避免因拆分操作而可能引发的脏读问题。
12、全量本地缓存
如何解决加载慢的问题:对于数据量较小的情况,我们可以直接从数据库轮询获取数据。然而,面对大量数据时,这种方法会导致启动时间过长。为了加速程序启动,我们可以采用本地文件加载和数据库轮询加载相结合的策略(时间戳看增量数据,启动过程中的数据)。
如何解决实时性和一致性问题:对于那些对实时性要求不高的场景,我们可以设定一个时间间隔,定期从数据库轮询获取更新的数据。但是,如果业务需要更高的实时性,我们可以采用 RocketMQ 广播消费的方式,以实现更快速的数据同步(MQ数据来源:Canal),最好还要有定期对账机制。
如何解决本地缓存过大问题:我们可以采用分片集群的思想,将数据分散加载到不同的服务集群中,从而降低单机内存的负担。
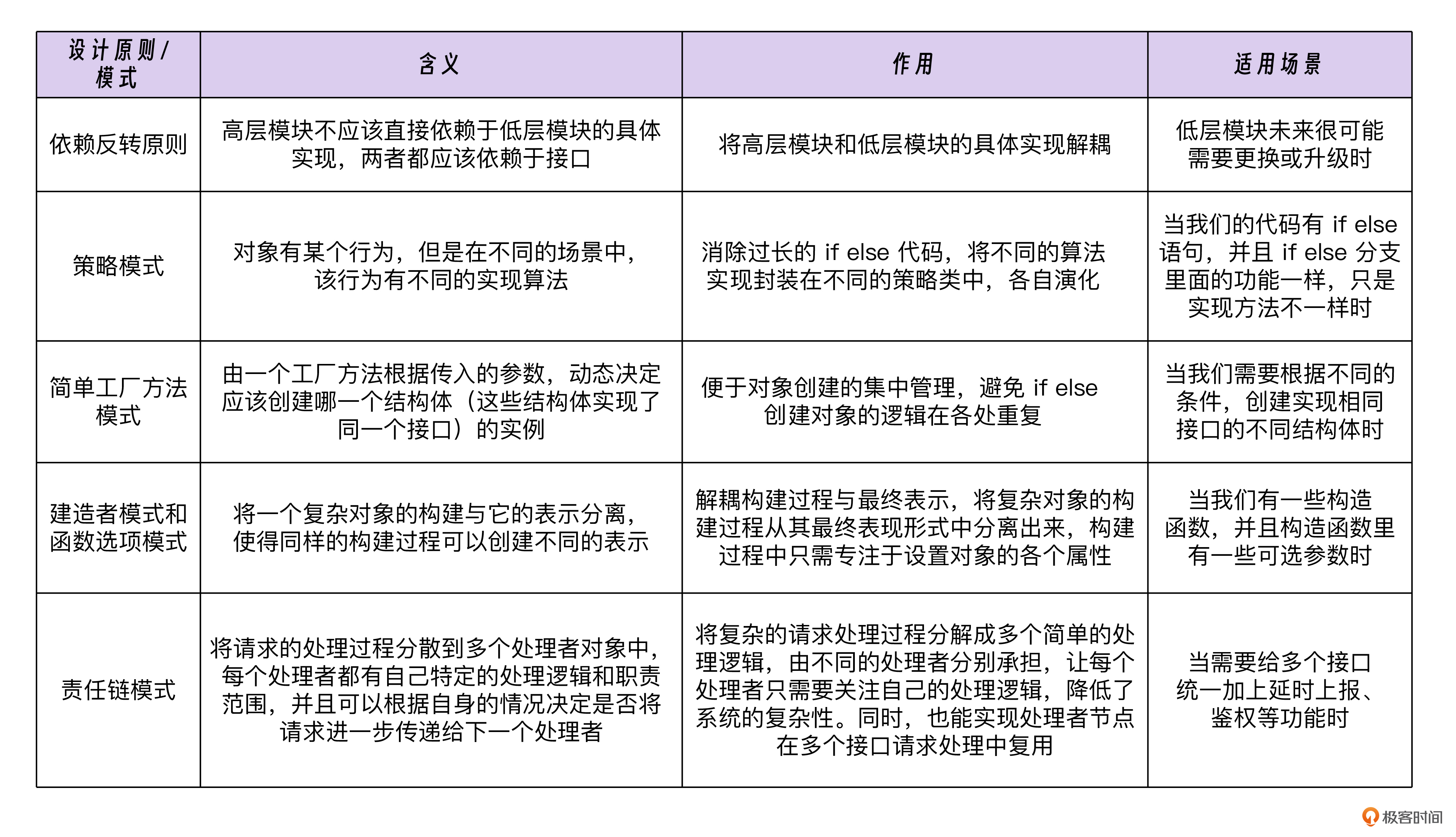
13、设计模式
14、如何编写相似函数
反射、泛型
15、代码编写陷阱
- 接口变量判空问题。接口变量在底层会储存类型 T 和值 V 这两个关键元素。当值为 nil 但类型不为 nil 时,就可能出现类似 “nil 不等于 nil” 这种看似矛盾的奇怪现象。
- 循环变量的使用问题。在 Go 1.22 版本之前,循环迭代变量的作用域涵盖整个循环体。如果我们在循环内部直接使用这个变量,极有可能引发一些令人困惑的
- 问题。
- 数值类型的JSON反序列化问题。当我们采用 map[string]interface{} 类型对 JSON 字符串进行反序列化操作时,会发现 int 类型悄然变成了 float64 类型的诡异现象。
- 最后还有并发原语和库的使用问题。如果 WaitGroup 和 channel 使用不当,程序不仅可能出现错误,还极有可能导致协程泄漏,对程序的稳定性造成严重影响。
16、日志和错误码


17、mock
1 | import ( |
18、超时和重试
超时时间:基于调用下游服务的p99延时(99%的请求都在这个时间内返回),外加一定的冗余时间作为超时时间。而且为了尽量避免无意义的等待,这个超时时间应该小于上游调用我们服务设置的超时时间。
重试次数:实践经验,我们一般设置成2-3次,而且这个重试次数,需要小于上游超时时间除以我们调下游的超时时间,避免无效重试(最好还要设置重试阈值熔断)。
19、熔断和降级
熔断:熔断器的核心实现逻辑是一个状态机,分别在打开状态、断开状态、半打开状态之间转换。
降级:降级的常见策略有返回兜底数据、异步处理和关闭非核心功能三种方案。
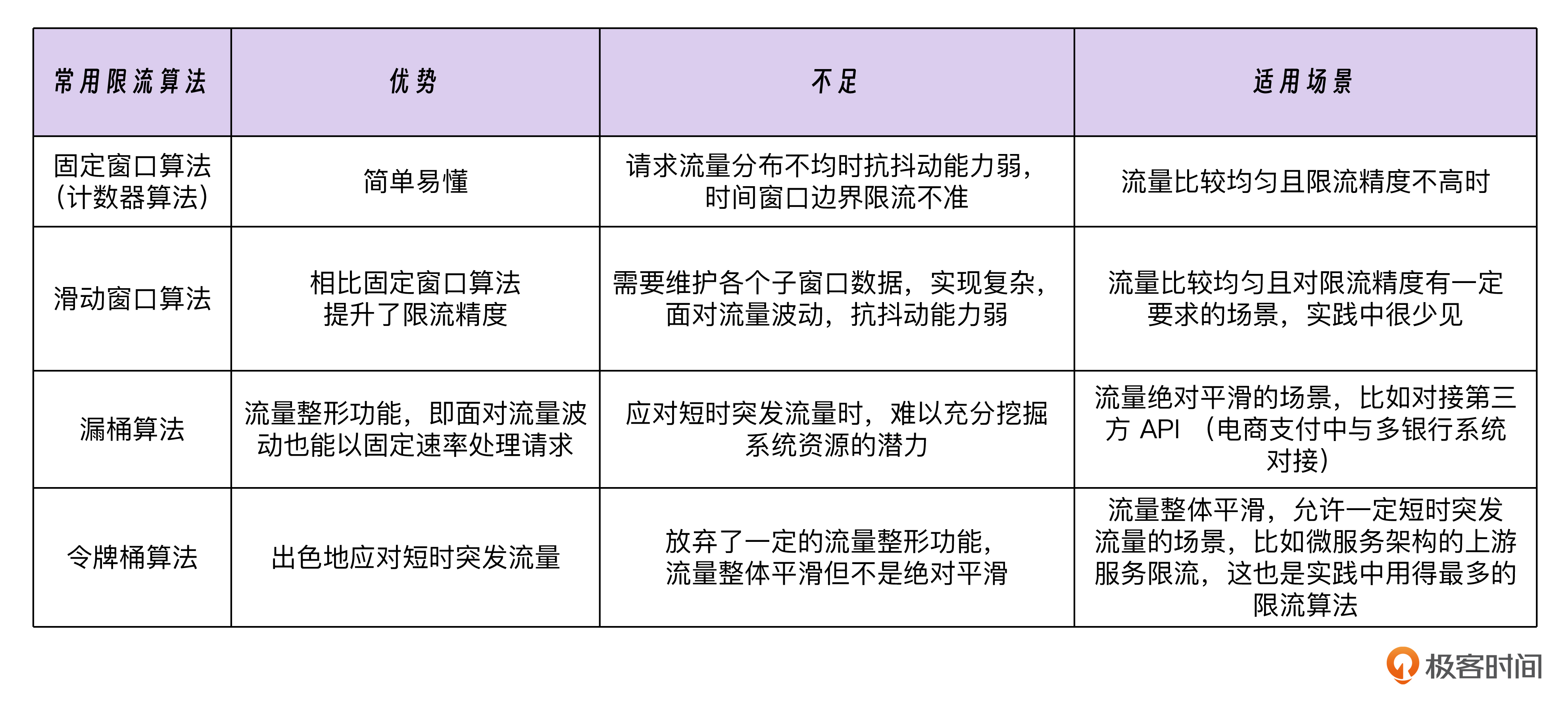
20、限流
21、故障隔离
数据隔离:
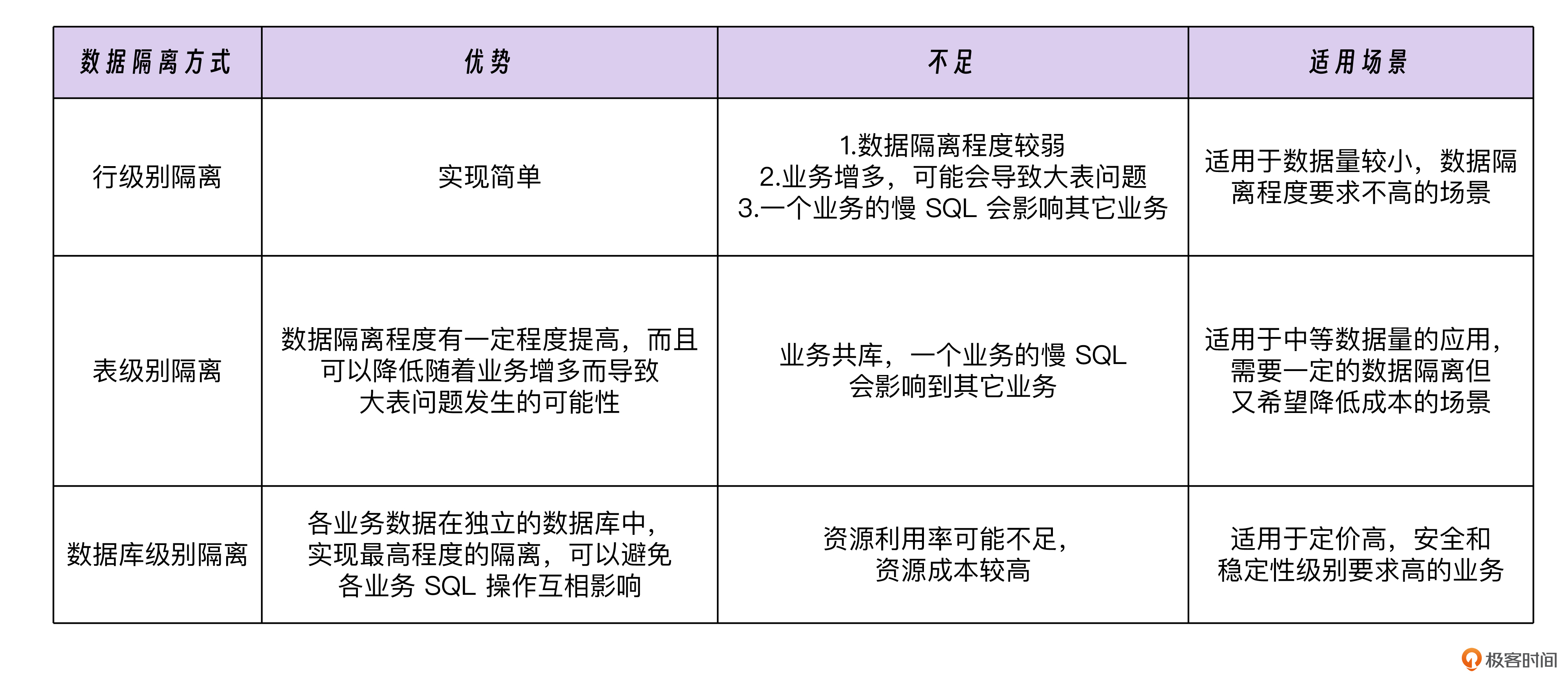
集群隔离:根据请求的不同,我们通常会把在线请求和离线请求分别部署在不同的集群中,同时,也会对在线请求进一步按照核心和非核心的区别来拆分集群。
服务拆分:为避免其他接口的迭代过程对核心接口产生影响,我们有时候可以考虑将核心接口单独拆分成独立的服务。
22、部署策略
- 停机部署:在这种部署方式下,在发布新版本时,我们需要先停止服务的运行,待新版本的代码和配置准备好之后,再重新启动服务。
- 蓝绿部署:在实施蓝绿部署时,除了正在运行稳定版本代码的线上蓝环境外,我们还需要搭建一套全新的绿环境,并且将绿环境中的代码更新为即将发布的新版本。当在绿环境中的各项测试与验证都确认无误后,再通过流量调度,逐步将线上流量从蓝环境切换到绿环境。(资源成本相对较高)
- 滚动部署。滚动部署是一种按比例分批将新版本部署到各个服务器的策略,它的操作流程如下:首先,根据预设的滚动比例,将部分服务器从 Consul等服务注册系统中暂时移除,以此中断线上流量对这些服务器的调用。随后,对这些已移除的服务器进行升级操作,待升级完成后,再将它们重新注册回 Consul 等系统中。最后,上游服务能够借助 Consul 等再次发现这些服务器,并把流量引导至这些已经部署了新版本代码的服务器上。当然,如果在滚动更新过程中发现任何问题,我们可以暂停后续更新并执行回滚;如果一切顺利,就可以继续下一轮滚动更新(资源利用效率高。但是进行部署还是回滚操作,所耗费的时间都相对较长)
- 灰度部署:灰度部署借鉴了煤矿工人使用金丝雀检测有害气体的做法,先将新版本代码部署到一小部分特定的服务器(单独配置监控),通过观察他们的使用情况来判断新版本是否存在问题(和滚动部署相比,灰度部署的优势在于能够先把新版本部署到某些特定的灰度机器上,并且会提前为这些灰度机器配置单独的监控。通过这种方式,我们更加容易发现新版本可能潜藏的问题,进而有效降低发布风险)
在实际操作过程中,很多公司会采用灰度部署和滚动部署相结合的发布策略。首先将新版本部署到灰度机器上,对它们的运行情况进行一段时间的观察,确认没有问题之后,再按照一定的比例,采用滚动部署的方式对其他机器进行更新,最终实现全量发布。
- 标题: Go服务开发Tips
- 作者: 纸鸢
- 创建于 : 2025-01-06 21:50:33
- 更新于 : 2025-04-07 01:19:15
- 链接: https://www.youandgentleness.cn/2025/01/06/Go服务开发Tips/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。