题记 本文主要记录例如etcd,Hystrix,Jaeger等一系列组件的使用,当然还有一些非组件用法的介绍。
Heartbeat 分布式系统架构中会有多个节点(node),有的是多个不同的节点服务,有的是多个一样的服务节点。这些节点分担着任务的运行、计算、或者程序逻辑的处理,如果一个节点出现了故障有时将使整个系统无法工作。
心跳机制就应运而生,心跳检测类似于ICU患者的心跳检测仪,对被检测者起到一个检测的作用。
以固定的频率向其他节点汇报当前节点状态的方式,收到心跳后一般认为当前节点和网络拓扑是良好的。在进行汇报时也携带上元数据等信息,方便管理中心进行管理
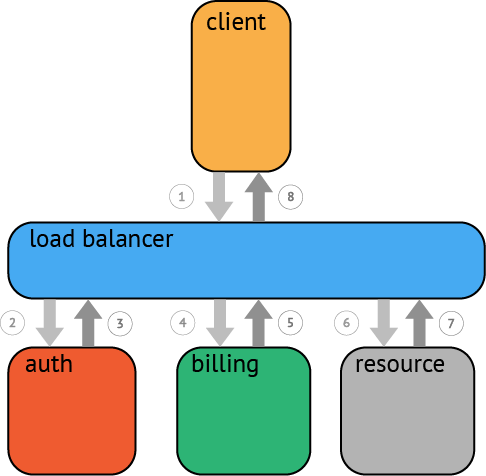
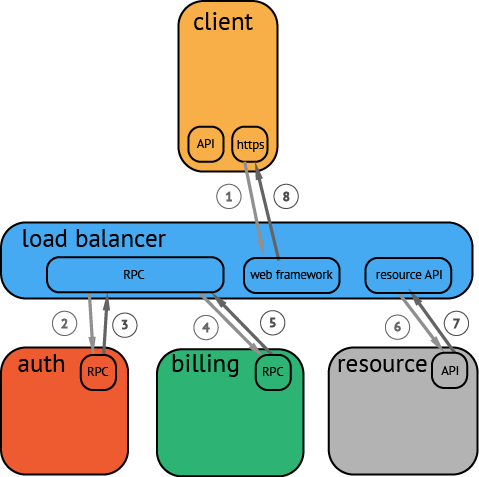
如上图所示,当客户端请求server(个人感觉这里这个server应该叫配置中心,比如etcd)中某个数据时,server需要到具体的node节点上进行请求,假设当前某个请求需要使用node1节点参与执行,那么就需要确保node1 节点是正常的。
单方面传递心跳的弊端
若server收不到node1的心跳,则说明node1失去了联系,但是并不一定是出现故障,也有可能出现node1服务处于繁忙状态,导致心跳传输超时。也有可能是server于node1之间的网络链路出现故障或者闪断,所以这种单方面传递的心跳不是万能的。
解决方案
使用周期性检测心跳机制:server每隔s秒向各个node发送检测请求,设定一个超时时间,如果超过超时时间,则进入死亡列表。
累计失效检测机制:在1 的基础之上,统计一定周期内节点的返回情况,以此来计算节点的死亡概率(超过超时次数/总检测次数)。对于死亡列表中的节点发起有限次数的重试,来做进一步判断。
对于设定的概率进行比对如果达到设定的概率可以进行一个真实踢出局的操作
go-micro使用示例
go-micro是重新注册服务和服务注册超时来保证的服务节点是否时可用的。
1 2 3 4 5 service := micro.NewService( micro.Name("com.example.srv.foo" ), micro.RegisterTTL(time.Second*30 ), micro.RegisterInterval(time.Second*15 ), )
etcd 什么是etcd
Etcd 是一个开源的分布式键值存储系统,它被设计用来在分布式系统中存储配置信息、元数据和其他类型的键值数据。Etcd 是由 CoreOS 开发并维护的,它使用 Raft 一致性算法来保证数据的一致性和可靠性。Etcd 提供了简单的 HTTP API 来访问和管理存储的数据。
服务注册和发现
在微服务架构中,服务注册和服务发现是非常重要的一部分。服务注册是指将微服务的实例信息(例如 IP 地址、端口号等)注册到一个中心化的服务注册表中,而服务发现则是指客户端根据服务的名称或其他标识从注册表中获取服务实例的信息,以便能够与之通信。
为什么使用etcd做服务注册和服务发现
使用 Etcd 作为服务注册和服务发现的中心化存储有以下好处:
分布式一致性 : Etcd 使用 Raft 算法来保证数据的一致性,这意味着即使在面临网络分区或节点故障的情况下,系统仍然能够保持稳定的状态。
高可用性 : Etcd 支持数据的复制和故障转移,可以配置多个节点来提高系统的可用性,即使某些节点发生故障,系统仍然可以继续运行。
动态更新 : 微服务架构中的服务实例通常会动态地启动、停止或扩展,Etcd 提供了对服务注册表的动态更新支持,可以及时地反映出服务实例的变化。
简单的API : Etcd 提供了简单易用的 HTTP API,使得开发者可以轻松地与之交互,进行服务注册和服务发现的操作。
综上所述,使用 Etcd 作为服务注册和服务发现的中心化存储可以帮助构建可靠、高可用的微服务架构,并简化了服务之间的通信和管理。
go-micro使用示例
1 2 3 4 5 6 7 8 etcdReg := etcd.NewRegistry( registry.Addrs(fmt.Sprintf("%s:%s" , config.EtcdHost, config.EtcdPort)), ) microService := micro.NewService( micro.Name("CommentService" ), micro.Registry(etcdReg), )
Metadata
This is an example of sending metadata/headers.
HTTP headers sent to the micro api will be converted to metadata and forwarded on.
Contents
srv - an RPC service which extracts metadatacli - an RPC client that calls the service once
go-micro使用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 type Say struct {}func (s *Say) error { md, ok := metadata.FromContext(ctx) if !ok { rsp.Msg = "No metadata received" return nil } log.Printf("Received metadata %v\n" , md) rsp.Msg = fmt.Sprintf("Hello %s thanks for this %v" , req.Name, md) return nil } func main () service := micro.NewService( micro.Name("go.micro.srv.greeter" ), micro.RegisterTTL(time.Second*30 ), micro.RegisterInterval(time.Second*10 ), ) service.Init() hello.RegisterSayHandler(service.Server(), new (Say)) if err := service.Run(); err != nil { log.Fatal(err) } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 func main () service := micro.NewService() service.Init() cl := hello.NewSayService("go.micro.srv.greeter" , service.Client()) ctx := metadata.NewContext(context.Background(), map [string ]string { "User" : "john" , "ID" : "1" , }) rsp, err := cl.Hello(ctx, &hello.Request{ Name: "John" , }) if err != nil { fmt.Println(err) return } fmt.Println(rsp.Msg) }
这个示例展示了如何在微服务之间传递元数据或头部信息。srv 是一个服务端程序,它会提取传入请求的元数据信息,而 cli 是一个客户端程序,它会调用 srv 并发送一些元数据。元数据可以包含一些关于请求的额外信息,比如认证凭证、请求来源等 。这些元数据可以在服务端用于识别请求或执行一些特定的逻辑。
Mocking 什么是mock
mock是在测试过程中,对于一些不容易构造/获取的对象,创建一个mock对象来模拟对象的行为。比如说你需要调用B服务,可是B服务还没有开发完成,那么你就可以将调用B服务的那部分给Mock掉,并编写你想要的返回结果。
go-micro使用示例
编写一个mock结构体来实现helloservcie以便于mock测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 package mockimport ( "context" "go-micro.dev/v4/client" proto "micro_example_project/idl/hello" ) type mockGreeterService struct {} func (m *mockGreeterService) error ) { return &proto.Response{ Greeting: "Hello " + req.Name, }, nil } func NewGreeterService () return new (mockGreeterService) }
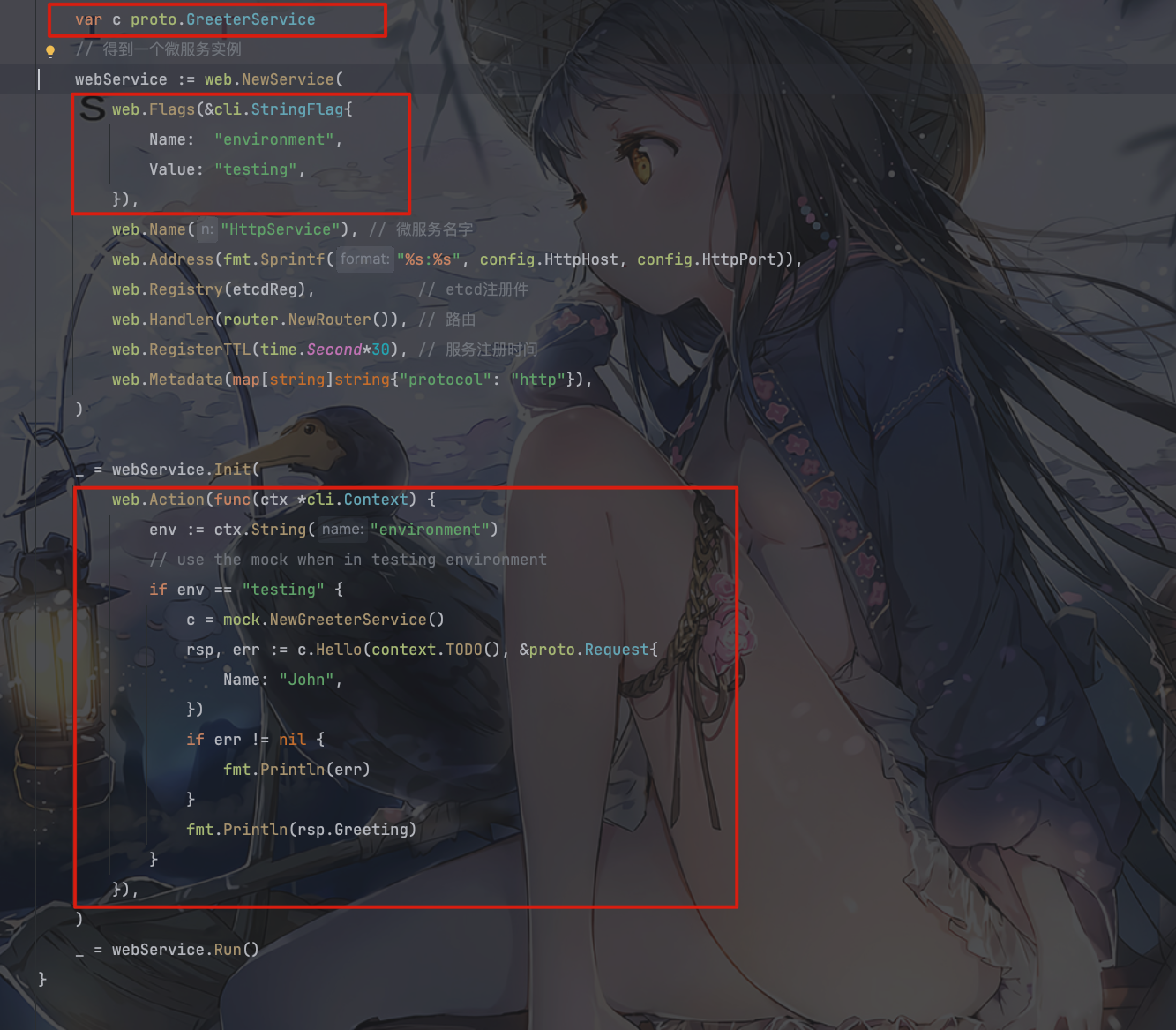
首先,你初始化了配置和 RPC。
然后,你创建了一个 Etcd 注册中心实例,并用它来初始化了一个 Web 服务实例。
在初始化 Web 服务的过程中,你使用了一个 web.Action,它会在服务启动时执行。在这个 Action 中,你获取了环境变量并检查了当前环境是否为 “testing”。
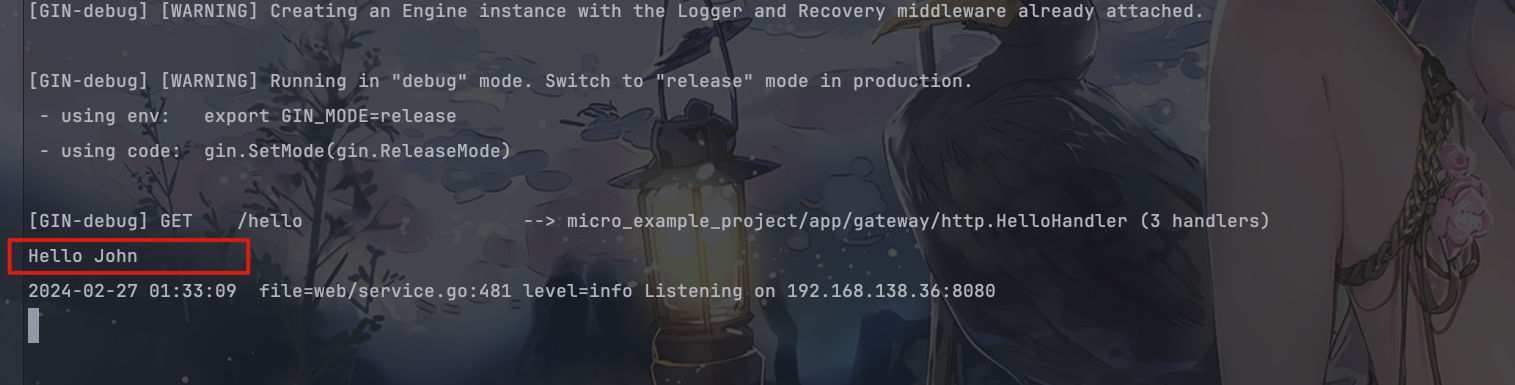
如果环境是 “testing”,则创建了一个名为 c 的 proto.GreeterService 实例,使用 mock.NewGreeterService() 创建了一个模拟的服务(本地函数调用)。
接着,调用模拟服务的 Hello 方法,并传入一个请求,请求中的 Name 设置为 “John”。然后输出返回的问候语。
最后,服务使用 _ = webService.Run() 启动,开始监听 HTTP 请求。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 package mainimport ( "context" "fmt" "github.com/go-micro/plugins/v4/registry/etcd" "github.com/urfave/cli/v2" "go-micro.dev/v4/registry" "go-micro.dev/v4/web" "micro_example_project/app/gateway/router" "micro_example_project/app/gateway/rpc" "micro_example_project/app/hello/mock" "micro_example_project/config" proto "micro_example_project/idl/hello" "time" ) func main () var c proto.GreeterService config.Init() rpc.InitRPC() etcdReg := etcd.NewRegistry( registry.Addrs(fmt.Sprintf("%s:%s" , config.EtcdHost, config.EtcdPort)), ) webService := web.NewService( web.Flags(&cli.StringFlag{ Name: "environment" , Value: "testing" , }), web.Name("HttpService" ), web.Address(fmt.Sprintf("%s:%s" , config.HttpHost, config.HttpPort)), web.Registry(etcdReg), web.Handler(router.NewRouter()), web.RegisterTTL(time.Second*30 ), web.Metadata(map [string ]string {"protocol" : "http" }), ) _ = webService.Init( web.Action(func (ctx *cli.Context) env := ctx.String("environment" ) if env == "testing" { c = mock.NewGreeterService() rsp, err := c.Hello(context.TODO(), &proto.Request{ Name: "John" , }) if err != nil { fmt.Println(err) } fmt.Println(rsp.Greeting) } }), ) _ = webService.Run() }
Redis 首先Go-Micro框架提供给我们关于Redis相关的插件,供我们在项目中使用Redis,但是由于它提供的插件代码十分的简陋不足以满足我们实际项目开发的需求,这里我们更倾向使用Go-Redis来帮助我们在项目中使用Redis。
Go-Micro框架的Redis插件项目地址:Plugins cache/redis
Go-Redis项目地址:Go Redis
这里我们就提供一个简单连接,并获取缓存值的示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package mainimport ( "context" "fmt" "github.com/redis/go-redis/v9" ) func main () ctx := context.Background() rdb := redis.NewClient(&redis.Options{ Addr: "localhost:6379" , Password: "" , DB: 0 , }) err := rdb.Set(ctx, "key" , "value" , 0 ).Err() if err != nil { panic (err) } val, err := rdb.Get(ctx, "key" ).Result() if err != nil { panic (err) } fmt.Println("key" , val) val2, err := rdb.Get(ctx, "key2" ).Result() if err == redis.Nil { fmt.Println("key2 does not exist" ) } else if err != nil { panic (err) } else { fmt.Println("key2" , val2) } }
具体其他的示例请访问对应的文档:Go-Redis文档
Logrus Go-Micro确实提供了一些日志包,但是它提供的太过于简单了,不足以够我们使用。我们这里使用Structured, pluggable logging for Go ,这个方便我们使用,接下来我们重点介绍一下它的使用。
先安装对应的第三方库:
1 go get github.com/sirupsen/logrus
简单的使用方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 package mainimport ( "github.com/sirupsen/logrus" "io" "os" ) func main () fileDebug, err := os.OpenFile("debug.log" , os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666 ) if err != nil { panic ("Failed to open debug log file: " + err.Error()) } defer fileDebug.Close() fileInfo, err := os.OpenFile("info.log" , os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666 ) if err != nil { panic ("Failed to open info log file: " + err.Error()) } defer fileInfo.Close() fileError, err := os.OpenFile("error.log" , os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666 ) if err != nil { panic ("Failed to open error log file: " + err.Error()) } defer fileError.Close() logger := logrus.New() logger.SetLevel(logrus.DebugLevel) logger.SetFormatter(&logrus.JSONFormatter{}) logger.SetOutput(io.Discard) logger.AddHook(NewFileHook(fileDebug, logrus.DebugLevel, logrus.DebugLevel)) logger.AddHook(NewFileHook(fileInfo, logrus.InfoLevel, logrus.InfoLevel)) logger.AddHook(NewFileHook(fileError, logrus.ErrorLevel, logrus.ErrorLevel)) logger.WithFields(logrus.Fields{ "key" : 1 , }).Info("1" ) logger.WithFields(logrus.Fields{ "key" : "value" , }).Error("2" ) logger.WithFields(logrus.Fields{ "key" : []byte {}, }).Debug("3" ) logger.Debug("This is a debug message" ) logger.Info("This is an info message" ) logger.Error("This is an error message" ) logger.Println("4" ) } type FileHook struct { file *os.File minLevel logrus.Level maxLevel logrus.Level } func NewFileHook (file *os.File, minLevel logrus.Level, maxLevel logrus.Level) return &FileHook{ file: file, minLevel: minLevel, maxLevel: maxLevel, } } func (hook *FileHook) error { if entry.Level >= hook.minLevel && entry.Level <= hook.maxLevel { line, err := entry.String() if err != nil { return err } _, err = hook.file.WriteString(line + "\n" ) return err } return nil } func (hook *FileHook) return logrus.AllLevels }
你可以输出到不同的日志文件中,方便你查询对应的问题。想要在整个项目使用它,可以var Logrus = logrus.New()在包开头声明,然后初始化不同级别的日志,请勿关闭日志,然后正常调用这个包的全局变量Logrus就可以。
Roundrobin 讲这个roundrobin之前,我先和大家介绍一下什么是负载均衡,什么是负载均衡算法?然后再讲这个roundrobin。
什么是负载均衡?
负载均衡就是一种计算机网络技术,用来在多个计算机(计算机集群)、网络连接、CPU、磁碟驱动器或其他资源中分配负载,以达到最佳化资源使用、最大化吞吐率、最小化响应时间、同时避免过载的目的。
负载均衡算法?
简单轮询:将请求按顺序分发给后端服务器上,不关心服务器当前的状态,比如后端服务器的性能、当前的负载。
加权轮询:根据服务器自身的性能给服务器设置不同的权重,将请求按顺序和权重分发给后端服务器,可以让性能高的机器处理更多的请求
简单随机:将请求随机分发给后端服务器上,请求越多,各个服务器接收到的请求越平均
加权随机:根据服务器自身的性能给服务器设置不同的权重,将请求按各个服务器的权重随机分发给后端服务器
一致性哈希:根据请求的客户端 ip、或请求参数通过哈希算法得到一个数值,利用该数值取模映射出对应的后端服务器,这样能保证同一个客户端或相同参数的请求每次都使用同一台服务器
最小活跃数:统计每台服务器上当前正在处理的请求数,也就是请求活跃数,将请求分发给活跃数最少的后台服务器
什么是roundrobin?
nginx的负载均衡调度算法默认就是 round robin,也就是轮询调度算法。算法本身很简单,轮着一个一个来,非常简单高效公平的调度算法。
go-micro中怎么使用roundrobin算法做负载均衡的?
1 2 3 microService := micro.NewService( micro.WrapClient(roundrobin.NewClientWrapper()), )
go-micro底层如何实现roundrobin?
底层代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 package roundrobinimport ( "sync" "go-micro.dev/v4/client" "go-micro.dev/v4/registry" "go-micro.dev/v4/selector" "context" ) type roundrobin struct { sync.Mutex rr map [string ]int client.Client } func (s *roundrobin) interface {}, opts ...client.CallOption) error { nOpts := append (opts, client.WithSelectOption( selector.WithStrategy(func (services []*registry.Service) var nodes []*registry.Node for _, service := range services { nodes = append (nodes, service.Nodes...) } return func () error ) { if len (nodes) == 0 { return nil , selector.ErrNoneAvailable } s.Lock() rr := s.rr[req.Service()] node := nodes[rr%len (nodes)] rr++ s.rr[req.Service()] = rr s.Unlock() return node, nil } }), )) return s.Client.Call(ctx, req, rsp, nOpts...) } func NewClientWrapper () return func (c client.Client) return &roundrobin{ rr: make (map [string ]int ), Client: c, } } }
这段代码实现了一个基于轮询(round-robin)调用策略的客户端包装器(wrapper),用于微服务调用。
让我们逐步解释:
roundrobin 结构体 :
它包含一个 sync.Mutex 来确保并发安全,以及一个 rr map[string]int 来跟踪每个服务的调用计数器。
实现了 client.Client 接口,因此它本身可以被视为一个客户端。
Call 方法 :
实现了 client.Call 方法,用于实际的服务调用。
它使用了 WithSelectOption 来设置一个选择器策略,这个策略会在每次调用时选择下一个要调用的节点。
选择器策略的实现逻辑如下:
将所有服务的节点汇总到一个 nodes 列表中。
创建一个返回下一个节点的函数。
函数首先检查节点列表是否为空,如果是则返回错误 ErrNoneAvailable。
否则,它根据轮询计数器(rr)选择节点列表中的一个节点。
然后递增轮询计数器,确保下一次调用选择的是下一个节点。
最后,返回选定的节点。
NewClientWrapper 函数 :
返回一个 client.Wrapper 函数,这个函数会接收一个客户端并返回一个包装后的客户端。
包装后的客户端是 roundrobin 结构体的实例,初始化了调用计数器和原始客户端。
总的来说,这个包装器在每次调用微服务时都会基于轮询选择下一个节点,从而实现了轮询调用策略。
RateLimiter 什么是限流处理?
限流处理是一种控制系统资源使用率的策略,用于限制系统在一定时间内处理请求的数量或速率。这种策略可以在服务端或者客户端实施,以确保系统在高负载情况下仍能保持稳定运行。
限流处理的好处?
好处包括:
保护系统稳定性 :限流可以防止系统在高负载情况下被过多的请求压垮,从而保护系统免受过载而导致的崩溃或性能下降。
提高可用性 :通过限制请求的数量或速率,可以确保系统能够继续提供服务,即使在高负载情况下也能够保持可用。
资源保护 :限流可以确保系统的关键资源,如数据库连接、内存、CPU 等,不被过度占用,从而保护系统的稳定性和性能。
平滑流量控制 :通过限制请求的数量或速率,可以实现平滑的流量控制,避免突发性的请求导致系统不稳定。
预防恶意攻击 :限流可以防止恶意攻击通过大量请求来消耗系统资源,从而提高系统的安全性。
go-micro使用示例
1 2 3 microService := micro.NewService( micro.WrapHandler(ratelimit.NewHandlerWrapper(50000 )), )
go-micro底层实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package ratelimitimport ( "go-micro.dev/v4/client" "go-micro.dev/v4/server" "go.uber.org/ratelimit" "context" ) type clientWrapper struct { r ratelimit.Limiter client.Client } func (c *clientWrapper) interface {}, opts ...client.CallOption) error { c.r.Take() return c.Client.Call(ctx, req, rsp, opts...) } func NewClientWrapper (rate int , opts ...ratelimit.Option) r := ratelimit.New(rate, opts...) return func (c client.Client) return &clientWrapper{r, c} } } func NewHandlerWrapper (rate int , opts ...ratelimit.Option) r := ratelimit.New(rate, opts...) return func (h server.HandlerFunc) return func (ctx context.Context, req server.Request, rsp interface {}) error { r.Take() return h(ctx, req, rsp) } } }
这段代码实现了一个基于令牌桶算法的限流处理器,用于限制客户端和服务器端处理请求的速率。
主要组成部分包括:
clientWrapper 结构体 :
它包含了一个 ratelimit.Limiter,用于限制请求的速率。
实现了 client.Client 接口,因此它本身可以被视为一个客户端。
在 Call 方法中,每次调用 Call 时都会先通过限流器 (r) 获取令牌,如果令牌不足则会进行阻塞,直到获取到足够的令牌后才会执行实际的请求调用。
NewClientWrapper 函数 :
它接受一个 rate 参数,表示每秒允许的最大请求数量。
使用 ratelimit.New 函数创建一个令牌桶限流器,用于控制请求速率。
返回一个 client.Wrapper 函数,这个函数接受一个客户端,然后返回一个包装后的客户端。
包装后的客户端是 clientWrapper 结构体的实例,它将限流器和原始客户端结合起来,实现了限流功能。
NewHandlerWrapper 函数 :
类似于 NewClientWrapper,但是用于服务端。
它接受一个 rate 参数,表示每秒允许的最大请求数量。
返回一个 server.HandlerWrapper 函数,用于包装服务端的处理器函数。
包装后的处理器函数会在每次处理请求之前先通过限流器获取令牌,如果令牌不足则会进行阻塞,直到获取到足够的令牌后才会执行实际的处理逻辑。
总的来说,这段代码实现了基于令牌桶算法的限流处理器,可以在客户端和服务器端分别对请求的速率进行限制,以保护系统免受过载的影响。
什么是令牌桶算法?
令牌桶算法是一种用于限制请求速率的算法,它维护了一个固定容量的令牌桶,令牌以固定的速率往桶里填充。每当有一个请求到达时,需要从令牌桶中获取一个令牌,只有当令牌桶中有足够的令牌时,请求才会被允许通过,否则请求将被限制或延迟处理。
好处:
平滑控制请求速率: 令牌桶算法可以平滑地控制请求的速率,因为令牌是以固定的速率生成的,所以可以很好地适应系统的处理能力。
允许突发流量: 令牌桶算法允许短时间内的突发流量,只要令牌桶中有足够的令牌,就可以处理突发的请求。
简单有效: 令牌桶算法相对简单,容易实现和理解,并且在实际应用中表现良好。
缺点:
难以应对长时间的突发流量: 令牌桶算法难以应对长时间的大量请求,因为它的令牌生成速率是固定的,无法适应长时间的高峰请求。
对于短时间突发流量的处理不够灵活: 尽管令牌桶算法允许短时间内的突发流量,但令牌桶的容量有限,如果突发流量持续时间较长,可能会导致令牌桶耗尽,进而影响请求的处理速率。
需要定期维护令牌桶状态: 令牌桶算法需要定期维护令牌桶的状态,包括生成令牌和处理请求等,如果状态维护不及时,可能会影响算法的效果。
简单实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 type TokenBucket struct { capacity int tokens int rate int lastTime time.Time interval time.Duration mutex sync.Mutex } func NewTokenBucket (capacity, rate int ) return &TokenBucket{ capacity: capacity, tokens: capacity, rate: rate, lastTime: time.Now(), interval: time.Second / time.Duration(rate), } } func (tb *TokenBucket) bool { tb.mutex.Lock() defer tb.mutex.Unlock() now := time.Now() delta := int (now.Sub(tb.lastTime) / tb.interval) tb.tokens = tb.tokens + delta if tb.tokens > tb.capacity { tb.tokens = tb.capacity } tb.lastTime = tb.lastTime.Add(time.Duration(delta) * tb.interval) if tb.tokens > 0 { tb.tokens-- return true } return false }
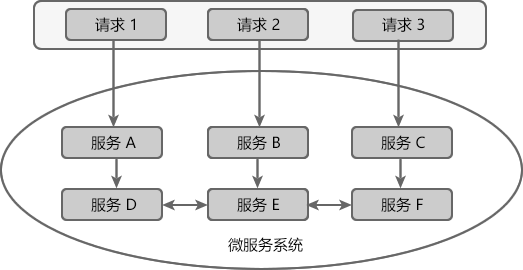
Hystrix 在微服务架构中,一个应用往往由多个服务组成,这些服务之间相互依赖,依赖关系错综复杂。
例如一个微服务系统中存在 A、B、C、D、E、F 等多个服务,它们的依赖关系如下图。
通常情况下,一个用户请求往往需要多个服务配合才能完成。如图所示,在所有服务都处于可用状态时,请求 1 需要调用 A、D、E、F 四个服务才能完成,请求 2 需要调用 B、E、D 三个服务才能完成,请求 3 需要调用服务 C、F、E、D 四个服务才能完成。
当服务 E 发生故障或网络延迟时,会出现以下情况:
即使其他所有服务都可用,由于服务 E 的不可用,那么用户请求 1、2、3 都会处于阻塞状态,等待服务 E 的响应。在高并发的场景下,会导致整个服务器的线程资源在短时间内迅速消耗殆尽。
所有依赖于服务 E 的其他服务,例如服务 B、D 以及 F 也都会处于线程阻塞状态,等待服务 E 的响应,导致这些服务的不可用。
所有依赖服务B、D 和 F 的服务,例如服务 A 和服务 C 也会处于线程阻塞状态,以等待服务 D 和服务 F 的响应,导致服务 A 和服务 C 也不可用。
从以上过程可以看出,当微服务系统的一个服务出现故障时,故障会沿着服务的调用链路在系统中疯狂蔓延,最终导致整个微服务系统的瘫痪,这就是“雪崩效应”。为了防止此类事件的发生,微服务架构引入了“熔断器”的一系列服务容错和保护机制。
熔断器
熔断器(Circuit Breaker)一词来源物理学中的电路知识,它的作用是当线路出现故障时,迅速切断电源以保护电路的安全。
在微服务领域,熔断器最早是由 Martin Fowler 在他发表的 《Circuit Breake r》一文中提出。与物理学中的熔断器作用相似,微服务架构中的熔断器能够在某个服务发生故障后,向服务调用方返回一个符合预期的、可处理的降级响应(FallBack),而不是长时间的等待或者抛出调用方无法处理的异常。这样就保证了服务调用方的线程不会被长时间、不必要地占用,避免故障在微服务系统中的蔓延,防止系统雪崩效应的发生。
Spring Cloud Hystrix
Spring Cloud Hystrix 是一款优秀的服务容错与保护组件,也是 Spring Cloud 中最重要的组件之一。
Spring Cloud Hystrix 是基于 Netflix 公司的开源组件 Hystrix 实现的,它提供了熔断器功能,能够有效地阻止分布式微服务系统中出现联动故障,以提高微服务系统的弹性。Spring Cloud Hystrix 具有服务降级、服务熔断、线程隔离、请求缓存、请求合并以及实时故障监控等强大功能。
Hystrix [hɪst’rɪks],中文含义是豪猪,豪猪的背上长满了棘刺,使它拥有了强大的自我保护能力。而 Spring Cloud Hystrix 作为一个服务容错与保护组件,也可以让服务拥有自我保护的能力,因此也有人将其戏称为“豪猪哥”。
在微服务系统中,Hystrix 能够帮助我们实现以下目标:
保护线程资源 :防止单个服务的故障耗尽系统中的所有线程资源。快速失败机制 :当某个服务发生了故障,不让服务调用方一直等待,而是直接返回请求失败。提供降级(FallBack)方案 :在请求失败后,提供一个设计好的降级方案,通常是一个兜底方法,当请求失败后即调用该方法。防止故障扩散 :使用熔断机制,防止故障扩散到其他服务。监控功能 :提供熔断器故障监控组件 Hystrix Dashboard,随时监控熔断器的状态。
Hystrix 服务降级
Hystrix 提供了服务降级功能,能够保证当前服务不受其他服务故障的影响,提高服务的健壮性。
服务降级的使用场景有以下 2 种:
在服务器压力剧增时,根据实际业务情况及流量,对一些不重要、不紧急的服务进行有策略地不处理或简单处理,从而释放服务器资源以保证核心服务正常运作。
当某些服务不可用时,为了避免长时间等待造成服务卡顿或雪崩效应,而主动执行备用的降级逻辑立刻返回一个友好的提示,以保障主体业务不受影响。
我们可以通过重写 HystrixCommand 的 getFallBack() 方法或 HystrixObservableCommand 的 resumeWithFallback() 方法,使服务支持服务降级。
Hystrix 服务降级 FallBack 既可以放在服务端进行,也可以放在客户端进行。
Hystrix 会在以下场景下进行服务降级处理:
程序运行异常
服务超时
熔断器处于打开状态
线程池资源耗尽
Go-micro使用示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 var Config = hystrix.CommandConfig{ Timeout: 1000 , RequestVolumeThreshold: 5000 , ErrorPercentThreshold: 50 , SleepWindow: 5000 , MaxConcurrentRequests: 50000 , } hystrix.ConfigureCommand("CommentList" , Config) err := hystrix.Do("CommentList" , func () error ) { res, err = rpc.CommentList(ctx, &req) if err != nil { return err } return err }, func (err error ) error { return err })
Go-micro底层解释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 func Do (name string , run runFunc, fallback fallbackFunc) error { runC := func (ctx context.Context) error { return run() } var fallbackC fallbackFuncC if fallback != nil { fallbackC = func (ctx context.Context, err error ) error { return fallback(err) } } return DoC(context.Background(), name, runC, fallbackC) } func DoC (ctx context.Context, name string , run runFuncC, fallback fallbackFuncC) error { done := make (chan struct {}, 1 ) r := func (ctx context.Context) error { err := run(ctx) if err != nil { return err } done <- struct {}{} return nil } f := func (ctx context.Context, e error ) error { err := fallback(ctx, e) if err != nil { return err } done <- struct {}{} return nil } var errChan chan error if fallback == nil { errChan = GoC(ctx, name, r, nil ) } else { errChan = GoC(ctx, name, r, f) } select { case <-done: return nil case err := <-errChan: return err } }
Kafka Kafka操作建议参考这个库:IBM/Sarama ,Go Document:IBM/sarama - Go Packages 。
关于Kafka的安装参考我之前的文章:Kafka学习 - Olivia的小跟班
生产者示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package mainimport ( "fmt" "github.com/IBM/sarama" ) func main () config := sarama.NewConfig() config.Producer.RequiredAcks = sarama.WaitForAll config.Producer.Partitioner = sarama.NewRandomPartitioner config.Producer.Return.Successes = true msg := &sarama.ProducerMessage{} msg.Topic = "web_log" msg.Value = sarama.StringEncoder("this is a test log2" ) client, err := sarama.NewSyncProducer([]string {"127.0.0.1:9092" }, config) if err != nil { fmt.Println("producer closed, err:" , err) return } defer client.Close() pid, offset, err := client.SendMessage(msg) if err != nil { fmt.Println("send msg failed, err:" , err) return } fmt.Printf("pid:%v offset:%v\n" , pid, offset) }
消费者示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package mainimport ( "fmt" "github.com/IBM/sarama" ) func main () consumer, err := sarama.NewConsumer([]string {"localhost:9092" }, nil ) if err != nil { fmt.Printf("fail to start consumer, err:%v\n" , err) return } partitionList, err := consumer.Partitions("web_log" ) if err != nil { fmt.Printf("fail to get list of partition:err%v\n" , err) return } fmt.Println(partitionList) for partition := range partitionList { pc, err := consumer.ConsumePartition("web_log" , int32 (partition), sarama.OffsetNewest) if err != nil { fmt.Printf("failed to start consumer for partition %d,err:%v\n" , partition, err) return } defer pc.AsyncClose() go func (sarama.PartitionConsumer) for msg := range pc.Messages() { fmt.Printf("Partition:%d Offset:%d Key:%v Value:%v" , msg.Partition, msg.Offset, msg.Key, string (msg.Value)) } }(pc) } select {} }
OpenTracing和Jaeger 为什么需要Tracing?
开发和工程团队因为系统组件水平扩展、开发团队小型化、敏捷开发、CD(持续集成)、解耦等各种需求,正在使用现代的微服务架构替换老旧的单片机系统。 也就是说,当一个生产系统面对真正的高并发,或者解耦成大量微服务时,以前很容易实现的重点任务变得困难了。过程中需要面临一系列问题:用户体验优化、后台真是错误原因分析,分布式系统内各组件的调用情况等。 当代分布式跟踪系统(例如,Zipkin, Dapper, HTrace, X-Trace等)旨在解决这些问题,但是他们使用不兼容的API来实现各自的应用需求。尽管这些分布式追踪系统有着相似的API语法,但各种语言的开发人员依然很难将他们各自的系统(使用不同的语言和技术)和特定的分布式追踪系统进行整合。
为什么需要OpenTracing?
OpenTracing通过提供平台无关、厂商无关的API,使得开发人员能够方便的添加(或更换)追踪系统的实现。 OpenTracing提供了用于运营支撑系统的和针对特定平台的辅助程序库。程序库的具体信息请参考详细的规范。
什么是一个Trace?
在广义上,一个trace代表了一个事务或者流程在(分布式)系统中的执行过程。在OpenTracing标准中,trace是多个span组成的一个有向无环图(DAG),每一个span代表trace中被命名并计时的连续性的执行片段。
分布式追踪中的每个组件都包含自己的一个或者多个span。例如,在一个常规的RPC调用过程中,OpenTracing推荐在RPC的客户端和服务端,至少各有一个span,用于记
一个父级的span会显示的并行或者串行启动多个子span。在OpenTracing标准中,甚至允许一个子span有个多父span(例如:并行写入的缓存,可能通过一次刷新操作写入动作)。
一个典型的Trace案例
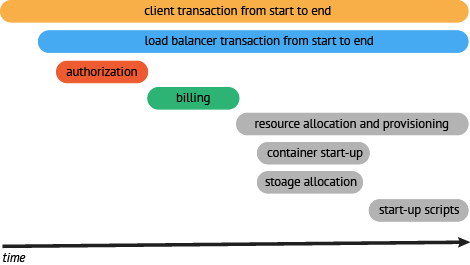
在一个分布式系统中,追踪一个事务或者调用流一般如上图所示。虽然这种图对于看清各组件的组合关系是很有用的,但是,它不能很好显示组件的调用时间,是串行调用还是并行调用,如果展现更复杂的调用关系,会更加复杂,甚至无法画出这样的图。另外,这种图也无法显示调用间的时间间隔以及是否通过定时调用来启动调用。一种更有效的展现一个典型的trace过程,如下图所示:
这种展现方式增加显示了执行时间的上下文,相关服务间的层次关系,进程或者任务的串行或并行调用关系。这样的视图有助于发现系统调用的关键路径。通过关注关键路径的执行过程,项目团队可能专注于优化路径中的关键位置,最大幅度的提升系统性能。例如:可以通过追踪一个资源定位的调用情况,明确底层的调用情况,发现哪些操作有阻塞的情况。
概念和术语
概念与术语 Opentracing文档中文版
什么是jaeger?
链路追踪之Jaeger安装&使用入门-CSDN博客
go-micro使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package wrapperimport ( "fmt" "io" "time" "github.com/opentracing/opentracing-go" "github.com/uber/jaeger-client-go" "github.com/uber/jaeger-client-go/config" ) var Tracer opentracing.Tracerfunc InitJaeger (serviceName string , jaegerHostPort string ) error ) { cfg := config.Configuration{ ServiceName: serviceName, Sampler: &config.SamplerConfig{ Type: jaeger.SamplerTypeConst, Param: 1 , }, Reporter: &config.ReporterConfig{ LogSpans: true , BufferFlushInterval: 1 * time.Second, LocalAgentHostPort: jaegerHostPort, }, } var closer io.Closer var err error Tracer, closer, err = cfg.NewTracer( config.Logger(jaeger.StdLogger), ) if err != nil { panic (fmt.Sprintf("ERROR: cannot init Jaeger: %v\n" , err)) } opentracing.SetGlobalTracer(Tracer) return Tracer, closer, err }
1 2 3 4 5 6 7 8 9 10 11 12 13 tracer, closer, err := wrapper.InitJaeger("CommentService" , fmt.Sprintf("%s:%s" , config.JaegerHost, config.JaegerPort)) if err != nil { fmt.Printf("new tracer err: %+v\n" , err) os.Exit(-1 ) } defer closer.Close()microService := micro.NewService( micro.WrapHandler(opentracing.NewHandlerWrapper(tracer)), micro.WrapClient(opentracing.NewClientWrapper(tracer)), )
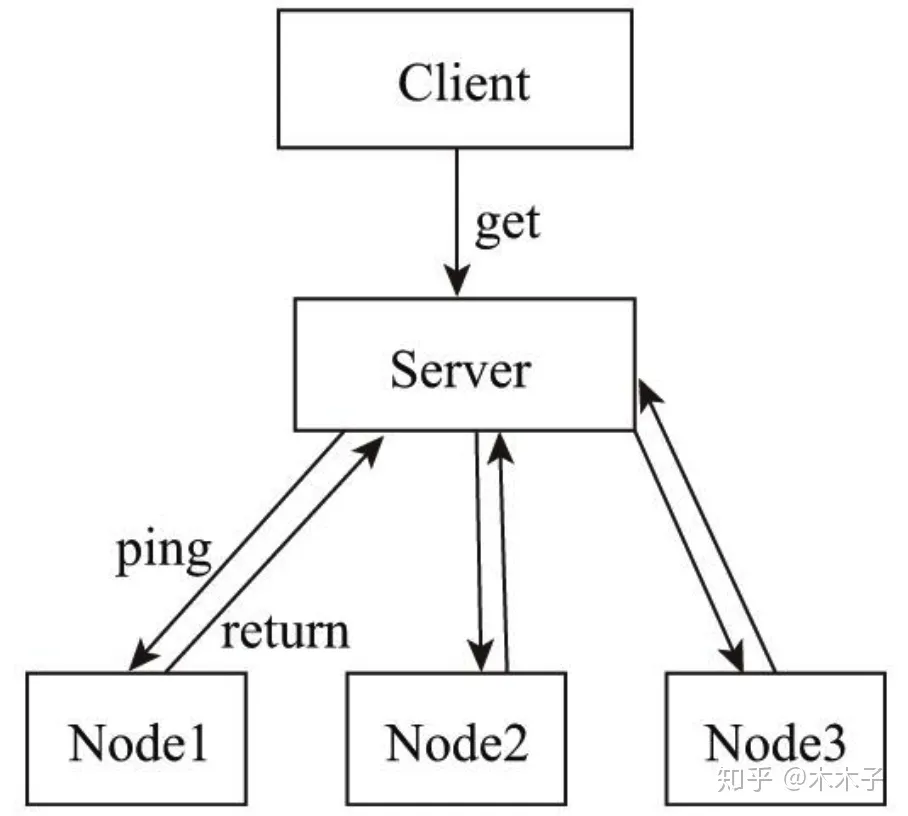

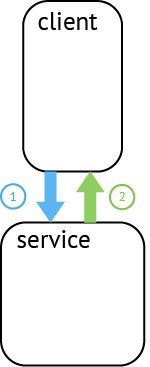
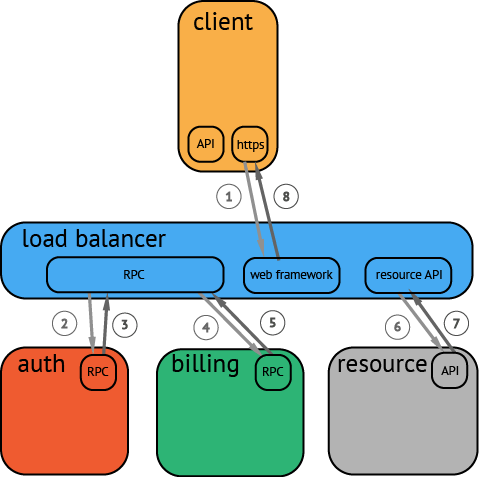 录RPC调用的客户端和服务端信息。
录RPC调用的客户端和服务端信息。